1000人ゲノムプロジェクト(1000 Genomes Project)は、異なる民族のヒトのゲノムサンプルを少なくとも1000人分以上解析し、遺伝的多様性のカタログを公開することを目指したプロジェクトで、2008年に開始されました。このプロジェクトはIGSRによって管理されている国際プロジェクトで、日本も含めた世界の26の集団からの3202人のゲノムデータが解析されています。
ここでは1000人ゲノムプロジェクトについてと、そのデータの利用方法について説明していきます。
[toc]1000人ゲノムプロジェクトの概要
- 1000人ゲノムプロジェクト:https://www.internationalgenome.org/
1000人ゲノムプロジェクトの主要な解析は「Pilot Analysis」「Phase 1 Analysis」「Phase 3 Analysis」の3つの解析から構成されています。それ以外にも各種の解析がなされており、それはすべて公共データベースからダウンロード可能となっています。
公開されているデータの入手
1000人ゲノムプロジェクトのデータはEMBL-EBI(欧州バイオインフォマティクス研究所)の公共データレポジトリで公開されていますが、こちらの「Data Portal」でデータの検索・ダウンロードができるようになっています。
なお、ここからダウンロードできるデータにはHGDP (Human Genome Diversity Project)やSGDP (Simons Genome Diversity Project)などの1000人ゲノムプロジェクト以外の同様のプロジェクトのデータも含まれています。
1000人ゲノムプロジェクトで公開されているデータ形式はシークエンスデータ(*.fastqなど)、アラインメントデータ(*.bamなど)、バリアントデータ(*.vcfなど)です。
データ取得例:日本人のゲノムデータを取得してみる
Data Portalから日本人のゲノムデータを検索して取得してみましょう。
まずは「Filter by population」をクリックして、日本人を表す「Japanese in Tokyo, Japan」を選択しましょう。HGDPやSGDPのデータも条件に入れるのなら、それぞれ「Japanese in Japan (HGDP)」や「Japanese in Japan (SGDP)」にもチェックを入れます。
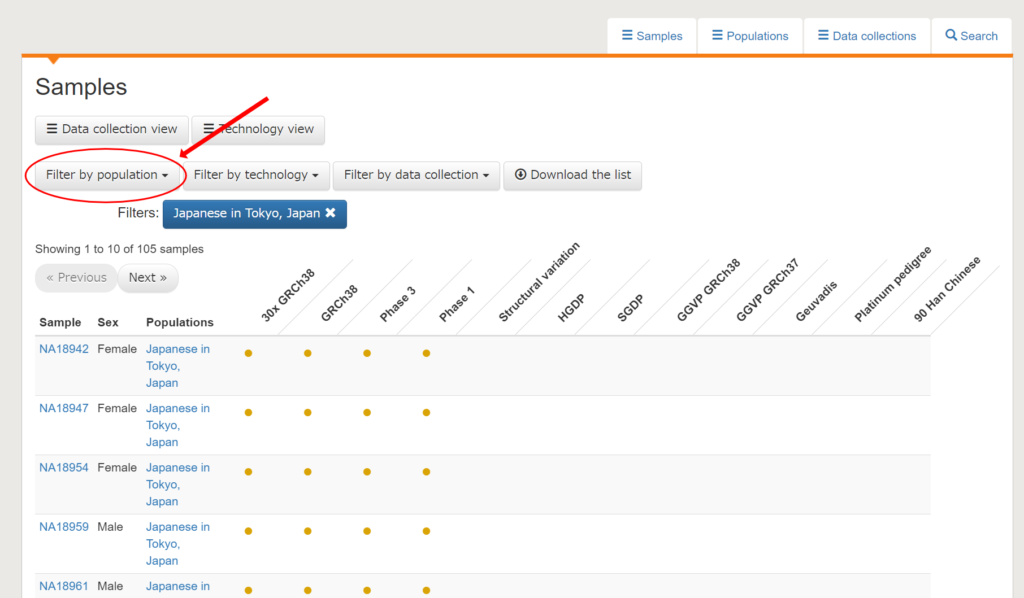
これで、日本人のデータを絞り込んで表示させることができました。Sampleの列に表示されている「NA18942」などというIDがゲノムデータを提供した人のIDです。ここでは、一番上の「NA18942」という人をクリックしてみましょう。
以下のように「NA18942」についての情報のポータルが表示されました。
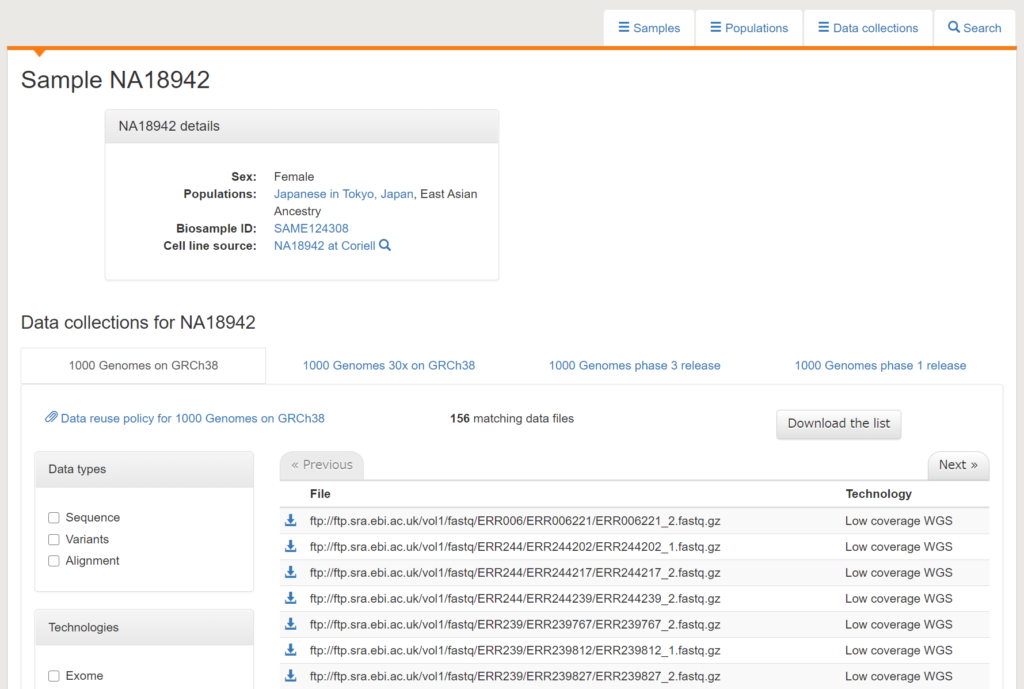
例えば、「Cell line source」の「NA18942 at Coriell」というところをクリックすると、Coriell Instituteで管理されているサンプルについての情報を見ることができます。以下のように、「NA18942」のサンプルは抹消静脈から採血で得られたBリンパ球のようです。
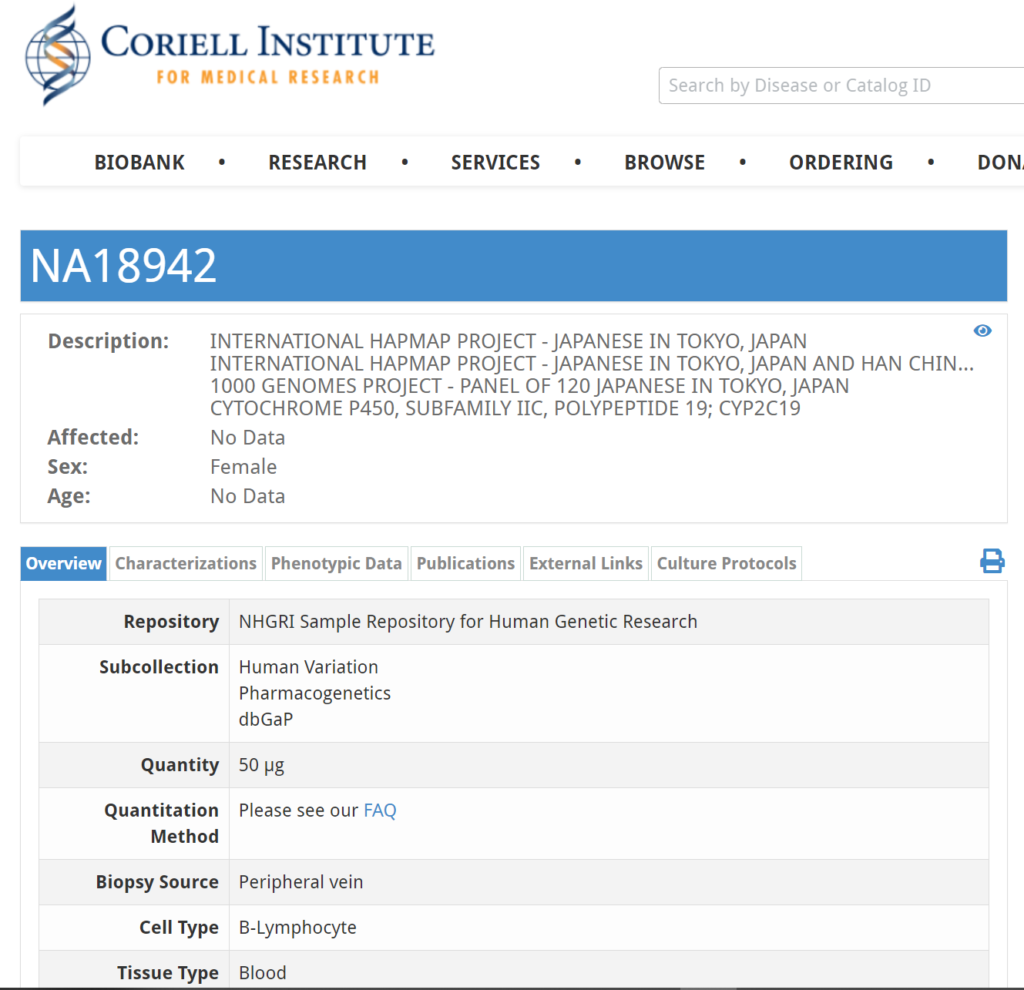
Coriell InstituteのページのPublicationsというところをクリックすると、このデータが関わる論文の一覧を見ることもできます。
続いて、先ほどの「NA18942」についてのポータルから必要なゲノム情報をダウンロードしてみましょう。1000人ゲノムプロジェクトでは、1つのサンプルを何回も解析しなおすことがよくなされています。Data collectionsのところの「1000 Genomes on GRCh38」「1000 Genomes 30x on GRCh38」「1000 Genomes phase 3 release」「1000 Genomes phase 1 release」はいずれも「NA18942」が解析されたプロジェクトを表しており、それぞれのプロジェクトごとに解析結果が格納されています。
例えば、「1000 Genomes phase 3 release」で得られたシークエンスデータを取得するには、以下のように「1000 Genomes phase 3 release」のタブを選んだ上で、左側のData typesからSequenceのチェックを入れます。そうすると以下のように条件に合うデータが一覧が表示されます。
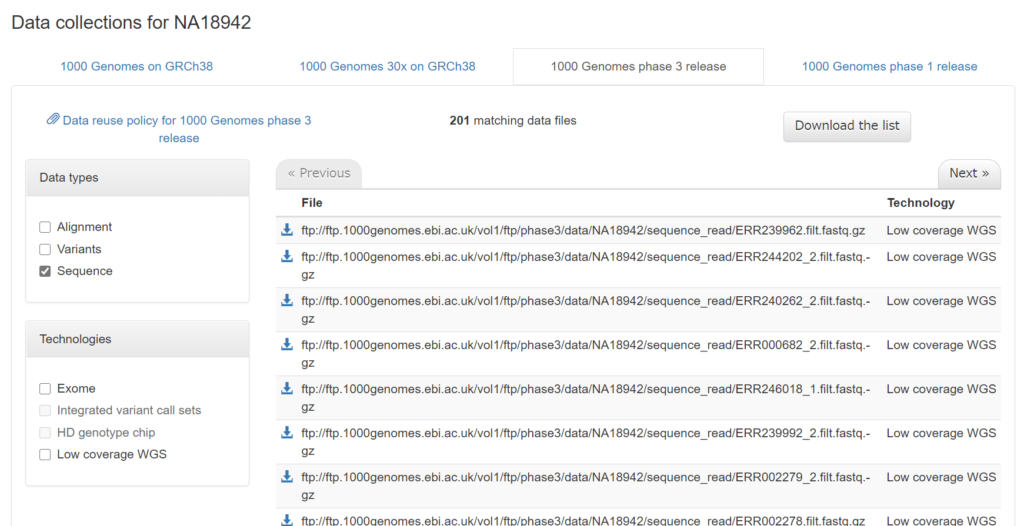
欲しいデータが見つかったら、ダウンロードマークをクリックしてブラウザから直接ダウンロードするか、ここに表示されているFTPのパスをコピーしてLinuxのcurlコマンドなどでダウンロードを行います。FTPのダウンロードに関しては以下の記事もご覧ください。








コメント