データ解析にはDataFrameやSeriesが非常に有用ですが、場合によっては最も単純なデータ形式であるリスト形式が必要になる場面もあります。DataFrameからリストとして取得したいデータをSeriesとして抽出してから、Seriesのto_listメソッドを用いることでリストに変換できます。
開発環境
- pandas 1.0.3
- Python 3.7.7

サンプルデータ
サンプルデータとして以下のデータを用います。
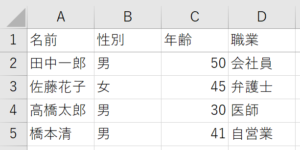
以下のようにURLを指定して、DataFrameとして取得できます。
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
DataFrameの行・列をリストに変換する
リストに変換する行や列をSeriesとして抽出してから、to_listメソッドでリストに変換します。なお、DataFrameから特定の行や列をSeriesとして抽出する方法については以下をご覧ください。

特定の列をリストに変換する
(例) サンプルデータの「名前」の列の値をリストに変換してみましょう。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
list_sample = df['名前'].to_list()
print(list_sample)
['田中一郎', '佐藤花子', '高橋太郎', '橋本清']
特定の行をリストに変換する
(例) サンプルデータの4行目の値をリストに変換してみましょう。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
list_sample = df.iloc[3].to_list()
print(list_sample)
['橋本清', '男', 41, '自営業']
DataFrame全体をリストに変換する
DataFrame全体をリストに変換する場合は、DataFrame自体にはリストに変換するためのメソッドが備わっていないので、一度numpy.ndarrayに変換してからリストに変換するのが定石となります。
まずはDataFrameをto_numpyメソッドでnumpy.ndarrayに変換しましょう。なお、DataFrameからvalues属性を用いてnumpy.ndarrayに変換する方法もありますが、APIドキュメントによればto_numpyメソッドの使用を推奨されています。これでDataFrameの行ラベル/列ラベル以外の要素が2次元のndarrayに変換されるので、さらにndarrayのtolistメソッドを用いてリストに変換します。
ここでできたリストは以下のように1つの行が1つのリストとなり、さらにそのリストが行ごとにリスト要素となっている入れ子型のリストになります。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
list_sample = df.to_numpy().tolist()
print(list_sample)
[['田中一郎', '男', 50, '会社員'], ['佐藤花子', '女', 45, '弁護士'], ['高橋太郎', '男', 30, '医師'], ['橋本清', '男', 41, '自営業']]
DataFrameの行ラベル / 列ラベルをリストに変換する
行ラベル / 列ラベルをリストに変換する場合は、それぞれindex属性、columns属性を用いてラベルをIndexオブジェクトとして取得し、to_listメソッドでリストに変換します。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
list_sample = df.columns.to_list()
print(list_sample)
['名前', '性別', '年齢', '職業']








コメント