pandasではそのままforループにDataFrameを入れると、ただ単に列ラベルが順番に返されるだけで、1行ずつデータを取り出すことはできません。ここではPythonのpandasモジュールを用いて、DataFrameのデータを1行ずつ取り出して順番に処理していく方法を説明します。
開発環境
- pandas 1.2.1
- Python 3.7.9
サンプルデータ
サンプルデータとして以下のデータを用います。
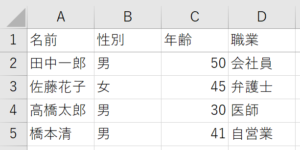
以下のようにURLを指定して、DataFrameとして取得できます。
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
DataFrameで行ごとにデータを取得する行う方法
DataFrameに対して直接forループを適用しても列ラベルが順番に返されるだけでDataFrameを1行ずつ処理することはできません。これはDataFrameの__iter__メソッドは列ラベルを表すイテレータを返すように定義されているからです。では、DataFrameから1行ずつ取り出して処理を行うにはどうしたらよいでしょうか?そのための方法としては次のようなものが用意されています。
iterrowsメソッドを使う
forループにiterrowsメソッドを用いることで、1行ずつ行ラベルとその行のデータ(Series型)のタプルを取得できます。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
for index, data in df.iterrows():
print(index)
print(data)
print('--------')
0
名前 田中一郎
性別 男
年齢 50
職業 会社員
Name: 0, dtype: object
--------
...中略...
--------
3
名前 橋本清
性別 男
年齢 41
職業 自営業
Name: 3, dtype: object
--------
この例ではiterrowsメソッドの戻り値のイテレータオブジェクトをforループで回し、得られた結果(タプル)を行ラベル(row)とデータ(data)に展開して取り出して表示しています。
ここで得られるその行のデータはSeries型なので、その要素へのアクセスは次のようにインデックスで指定するか項目名で指定するかのいずれかになります。
# インデックスで指定する
print(data[0])
# 項目名で指定する
print(data['名前'])
itertuplesメソッドを使う
forループにitertuplesメソッドを用いることで、1行ずつその行のデータから成るタプル(namedtuple)を取得できます。なお、このタプルの1番最初の項目は行ラベルとなっています。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
for data in df.itertuples():
print(data)
print('--------')
Pandas(Index=0, 名前='田中一郎', 性別='男', 年齢=50, 職業='会社員') -------- Pandas(Index=1, 名前='佐藤花子', 性別='女', 年齢=45, 職業='弁護士') -------- Pandas(Index=2, 名前='高橋太郎', 性別='男', 年齢=30, 職業='医師') -------- Pandas(Index=3, 名前='橋本清', 性別='男', 年齢=41, 職業='自営業') --------
この例ではitertuplesメソッドの戻り値のイテレータオブジェクトをforループで回し、得られた結果(タプル)を表示しています。このタプルはデフォルトではnamedtupleとなっていて、その要素へは通常のタプルと同様にインデックスでアクセスできるのに加えて、以下のように項目名でもアクセスすることもできます。
# インデックスで指定する
print(data[1])
# 項目名で指定する
print(data.名前)
項目名でアクセスする場合は日本語の項目名でもそのまま指定して問題なくプログラムは動作するようです。
ここで説明した2つの方法のうち、iterrowsメソッドを用いる方法は1行ずつSeriesインスタンスを作成するので処理に時間がかかってしまい、単にデータを取得するだけであればitertuplesメソッドを用いる方法の方が高速に処理できます。
DataFrameの一部の項目を行ごとに取得する方法
取得したいデータが一部の項目のみの場合は、DataFrameから直接1行ずつループ処理で取得するのではなく、必要な項目だけSeriesとして抜き取った上で、そのSeriesに対してループ処理を行った方が高速に処理できます。なお、Seriesはforループで回すと1つ1つの要素ずつ順番に取得することができます。
1つの項目のみ必要な場合
DataFrameから取得するデータが1つの項目のみである場合は、次のようにDataFrameからその列全体をSeriesとして取得してforループに入れましょう。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
for item in df['名前']:
print(item)
print('--------')
田中一郎 -------- 佐藤花子 -------- 高橋太郎 -------- 橋本清 --------
複数の項目が必要な場合
複数の項目が必要な場合は次のようにzip関数を用いて2つのSeriesを1つにまとめてforループに入れることで、タプルとして結果を得ることができます。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
for item in zip(df['名前'], df['性別']):
print(item)
print('--------')
('田中一郎', '男')
--------
('佐藤花子', '女')
--------
('高橋太郎', '男')
--------
('橋本清', '男')
--------
この時、次のようにDataFrameからデータを抽出するときにまとめて2つの項目を指定してしまうと、そこで得られる結果は「2つのSeries」ではなくて「DataFrame」になってしまうので注意してください。
# 得られる結果はDataFrame
df[['名前', '性別']]
# zip関数を用いることでSeriesをまとめられる
zip(df['名前'], df['性別'])
DataFrameのデータを行ごとに書き換える方法
iterrowsメソッドを用いて値を取得する方法は元のDataFrameのコピーを取得しているので、その値を更新しても元のDataFrameは更新されません。
例えば次の例のようにサンプルデータの’名前’を1行ずつ更新しようとしても、元のDataFrameは変わりません。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
for index, data in df.iterrows():
data['名前'] = '匿名'
print(df)
名前 性別 年齢 職業 0 田中一郎 男 50 会社員 1 佐藤花子 女 45 弁護士 2 高橋太郎 男 30 医師 3 橋本清 男 41 自営業
またitertuplesメソッドで得られる結果はタプルなので、そもそも新たな値を代入することすらできません。
そこでDataFrameのデータを行ごとに書き換えるには、次のようにしてforループで書き換えるデータの行ラベル・列ラベルを取得した上で、元のDataFrameにその行ラベル・列ラベルを用いてアクセスして直接値を代入する必要があります。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
for index, data in df.iterrows():
df.loc[index, '名前'] = '匿名'
print(df)
名前 性別 年齢 職業 0 匿名 男 50 会社員 1 匿名 女 45 弁護士 2 匿名 男 30 医師 3 匿名 男 41 自営業








コメント