統計解析する元データはcsvやExcel形式など様々な形式で収集されますが、Excelのデータは必ずしも解析に適した形で保存されているとは限りません。また、ビッグデータを扱うような巨大なデータベースの場合は、Excelでデータを保存するのは無理があります。そのような場合は、汎用形式ではなくデータを扱うために設計された専用のデータベース形式を用いてデータを集積するのが一番です。ここでは身近なデータベースソフトとしてMicrosoft Officeに含まれているAccessを使ってみましょう。
Microsoft Accessのデータベース形式は.accdb形式ですが、それをPythonからアクセスする方法を説明します。
なお、データベースを扱うためには、SQLの知識があった方がよいですが、ここで説明するように一度pandas.DataFrame形式として読み込んでしまえばSQLの知識はなくても解析できます。
開発環境
- Python 3.7.7
- Pandas 1.0.3
- pyodbc 4.0.30
pyodbcモジュールの取得
PythonからODBCを用いてデータベースに接続するためには、pyodbcモジュールを用います。AnacondaでPythonをインストールするとpyodbcも含まれていますが、まだpyodbcがインストールされていない場合は、condaから以下のようにインストールしましょう。
conda install pyodbc
ODBCはリレーショナルデータベースへアクセスするための共通インターフェースなので、pyodbcを用いればAccessのみならずSQL ServerやMySQL、SQLiteなどの各種データベースに接続することができます。
データベースエンジンをインストールする
Microsoft Access のデータベースエンジン
Microsoft Accessのデータベースエンジンには以下の2種類があります。従来からあるのがMicrosoft Jet データベースエンジンでWindowsに標準で組み込まれてきましたが、.accdbファイルには対応しておらず、また32ビット版しかありません。Microsoft Access 2007 以降の標準となっているデータベースエンジンはMicrosoft ACEとなっています。ただし、こちらはWindowsには標準では組み込まれておらず、自分でインストールする必要があります。
Microsoft Jet データベースエンジン
- Microsoft Access 2003 までのデータベースエンジン
- Jet 4.0 で開発終了
- 64ビット版の提供なし
Microsoft ACE データベースエンジン
- Microsoft Access 2007 以降のデータベースエンジン
- Jetとも下位互換性があり.mdbファイルの読み書きもできる
自分の環境のデータベースエンジンの確認・インストール
以下のプログラムを実行しインストールされているデータベースエンジンの一覧を取得します。
import pyodbc
print(pyodbc.drivers())
この結果に ‘Microsoft Access Driver (*.mdb, *.accdb)’ が含まれていれば、すでにAccessのデータベースエンジンがインストール済みですが、含まれていなければインストールする必要があります。以下から64ビット版をダウンロードし、インストールします。
もう一度、先ほどのプログラムを実行し、結果に ‘Microsoft Access Driver (*.mdb, *.accdb)’ が含まれるようになったことを確認してください。
Accessデータベースに接続する
サンプルデータベース
ここでは、「C:\BioTech-Lab」フォルダにSampleDB.accdbというファイル名で以下のデータベースを保存します。
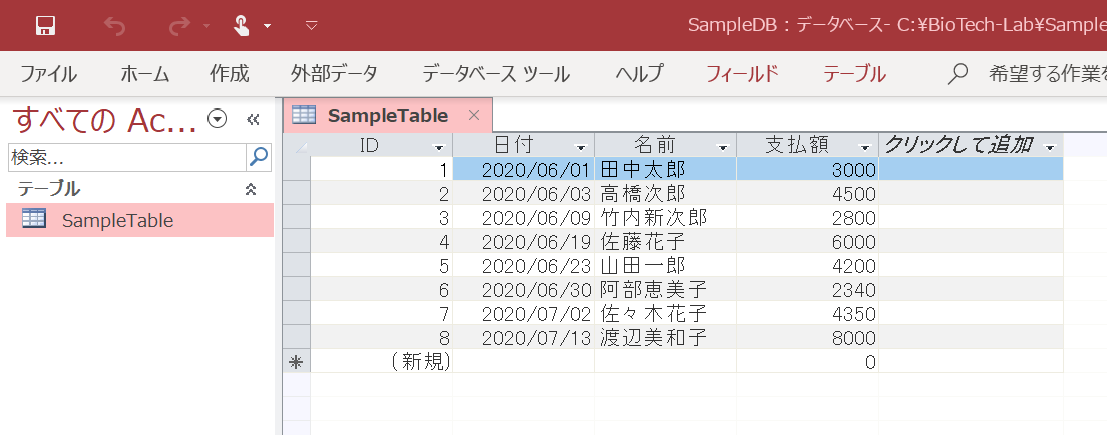
基本的なデータベースの操作方法
pyodbcを用いたMicrosoft Accessへの接続方法は公式ドキュメントに説明されています。
まず、pyodbcのconnect関数で新規のConnectionインスタンスを生成し、次にConnectionのcursorメソッドで新規のカーソル(=Cursorクラスのインスタンス)を生成します。
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\BioTech-Lab\SampleDB.accdb;'
)
conn = pyodbc.connect(conn_str)
カーソルを用いることで、データベースから検索結果を1件ずつ処理していくことができます。
なお、.accdbファイルをpandas.DataFrameとして読み込むのなら、pandas.read_sql関数にConnectionとSQLを渡すだけで簡単に取得することができます。
sql = 'SQL SELECT文'
df = pandas.read_sql(sql, conn)
データの追加・更新を行う
CursorクラスのexecuteメソッドにSQLのINSERT文やUPDATE文を指定し、commitメソッドを実行することでデータの追加・更新処理を実行できます。
sql = 'SQL INSERT文 / UPDATE文'
cursor.execute(sql)
cursor.commit()
データベースの接続を閉じる
CursorインスタンスのCloseメソッドでカーソルを閉じて、ConnectionインスタンスのCloseメソッドでConnectionを終了させます。
cursor.close()
conn.close()
pyodbcによるデータベース操作の例
データベースに含まれるテーブルの一覧を取得する
以下のようにしてサンプルDBに含まれるテーブルの一覧を取得してみましょう。
import pyodbc
# データベースに接続します
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\BioTech-Lab\SampleDB.accdb;'
)
conn = pyodbc.connect(conn_str)
cursor = conn.cursor()
# データベースに含まれるテーブルを取得します
for table_info in cursor.tables(tableType='TABLE'):
print(table_info.table_name)
# データベースの接続を閉じます
cursor.close()
conn.close()
SampleTable
これで、サンプルDBに含まれているテーブル名であるSampleTableが得られました。データベースにテーブルが複数含まれている場合は、その一覧を取得できます。
データベースのテーブルをDataFrameとして取得する
サンプルDBに含まれるSampleTableテーブルのデータをすべて取得します。その後の解析がしやすいようにpandas.DataFrameとしてデータを取得してみましょう。
import pyodbc
import pandas as pd
# データベースに接続します
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\BioTech-Lab\SampleDB.accdb;'
)
conn = pyodbc.connect(conn_str)
# データベースの指定したテーブルのデータをすべて抽出します
sql = 'SELECT * FROM SampleTable'
df = pd.read_sql(sql, conn)
print(df)
# データベースの接続を閉じます
conn.close()
ID 日付 名前 支払額 0 1 2020-06-01 田中太郎 3000 1 2 2020-06-03 高橋次郎 4500 2 3 2020-06-09 竹内新次郎 2800 3 4 2020-06-19 佐藤花子 6000 4 5 2020-06-23 山田一郎 4200 5 6 2020-06-30 阿部恵美子 2340 6 7 2020-07-02 佐々木花子 4350 7 8 2020-07-13 渡辺美和子 8000
DataFrameの作成方法は以下の記事をご覧ください。

なお、SQLを扱ったことのない方でも、SQLの一番基本的な以下の構文さえ理解すれば使うことができます。
SELECT * FROM テーブル名
これは「テーブル名」で指定したテーブルのすべてのデータを抽出するという命令で、テーブル名にデータを取得したいテーブルの名前を指定します。
条件を満たすデータをDataFrameとして取得する
大規模なデータベースの場合は、すべてのデータを取得して解析するのは非効率な場合もあります。ここでは、取得するデータを条件で絞って解析する方法を見ていきましょう。
サンプルDBに含まれるSampleTableテーブルから2020年6月のデータだけを抽出して、pandas.DataFrameとして取得してみます。条件の指定はSQLのSELECT文のWHERE句で行います。なお、Microsoft Accessで日付を表すときは#で囲む必要があります。
import pyodbc
import pandas as pd
# データベースに接続します
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\BioTech-Lab\SampleDB.accdb;'
)
conn = pyodbc.connect(conn_str)
# データベースの指定したテーブルのデータのうち、指定された条件のものを抽出します
sql = 'SELECT * FROM SampleTable WHERE 日付 BETWEEN #2020/6/1# AND #2020/6/30#'
df = pd.read_sql(sql, conn)
print(df)
# データベースの接続を閉じます
conn.close()
ID 日付 名前 支払額 0 1 2020-06-01 田中太郎 3000 1 2 2020-06-03 高橋次郎 4500 2 3 2020-06-09 竹内新次郎 2800 3 4 2020-06-19 佐藤花子 6000 4 5 2020-06-23 山田一郎 4200 5 6 2020-06-30 阿部恵美子 2340
これで2020年6月のデータだけ抽出できました。
名前で抽出する場合や、ワイルドカードを使う場合などは以下のようになります。
# 「田中太郎」のデータを抽出する
sql = "SELECT * FROM SampleTable WHERE 名前='田中太郎'"
# 名前が「田」で始まる人を抽出する(ワイルドカードを用いる)
sql = "SELECT * FROM SampleTable WHERE 名前 LIKE '田%'"
SQL上で文字列を扱うときは ‘ (クォーテーション)で囲む必要があるので、SQL文自体は ” (ダブルクォーテーション)で囲みましょう。また、使えるワイルドカードは以下の通りです。
- %:0文字以上の任意の文字列
- _:任意の一文字
データベースにデータを追加する
SQLのINSERT文を用いることでテーブルにデータを追加することができます。データの操作を行う場合は、CursorクラスのexecuteメソッドでSQLを実行してから、commitメソッドでデータの更新をする必要があります。
import pyodbc
# データベースに接続します
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\BioTech-Lab\SampleDB.accdb;'
)
conn = pyodbc.connect(conn_str)
cursor = conn.cursor()
# データベースにデータを追加します
sql = "INSERT INTO SampleTable(日付, 名前, 支払額) VALUES(#2020/7/19#, '山中一郎', 3900)"
cursor.execute(sql)
cursor.commit()
# データベースの接続を閉じます
cursor.close()
conn.close()
これで、このようにデータが追加されました。
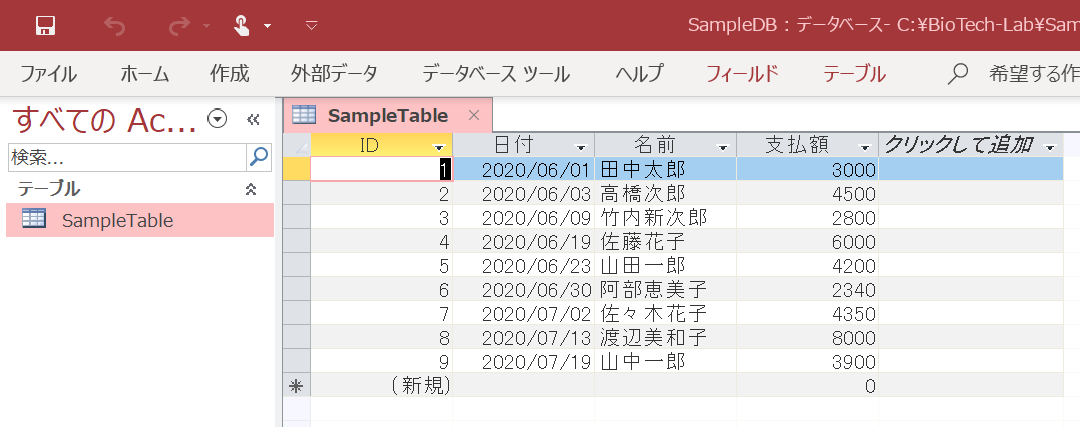
なお、IDはAccessでオートナンバー型にしているので、INSERT文で指定しなくても自動的に割り振られます。
データベースのデータを更新する
SQLのUPDATE文を使うことでデータの更新を行うことができます。先ほどと同様に、CursorクラスのexecuteメソッドでSQLを実行してから、commitメソッドでデータの更新をする必要があります。
import pyodbc
# データベースに接続します
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\BioTech-Lab\SampleDB.accdb;'
)
conn = pyodbc.connect(conn_str)
cursor = conn.cursor()
# データベースの「山中一郎」の支払額を変更します
sql = "UPDATE SampleTable SET 支払額=4000 WHERE 名前='山中一郎'"
cursor.execute(sql)
cursor.commit()
# データベースの接続を閉じます
cursor.close()
conn.close()
これで、先ほど追加した山中一郎さんの支払額を変更できました。
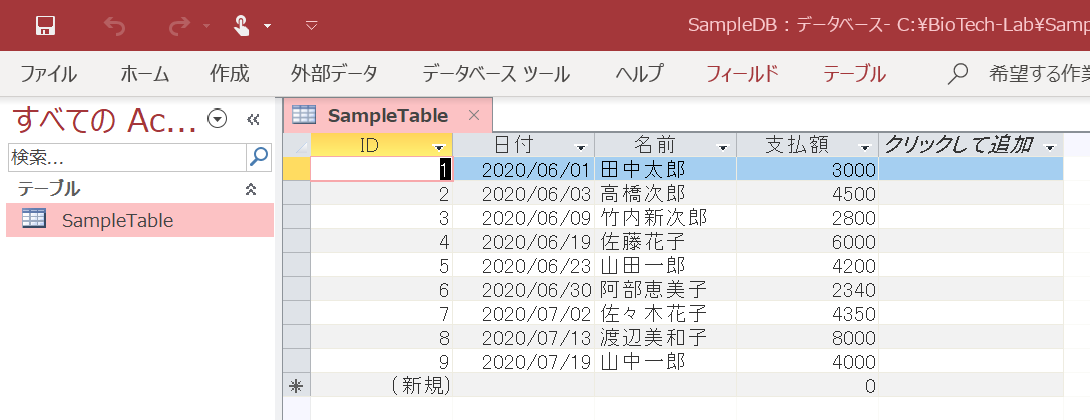
データベースのデータを削除する
SQLのDELETE文を使うことでデータの更新を行うことができます。先ほどと同様に、CursorクラスのexecuteメソッドでSQLを実行してから、commitメソッドでデータの更新をする必要があります。
import pyodbc
# データベースに接続します
conn_str = (
r'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};'
r'DBQ=C:\BioTech-Lab\SampleDB.accdb;'
)
conn = pyodbc.connect(conn_str)
cursor = conn.cursor()
# データベースから「山中一郎」のデータを削除する
sql = "DELETE FROM SampleTable WHERE 名前='山中一郎'"
cursor.execute(sql)
cursor.commit()
# データベースの接続を閉じます
cursor.close()
conn.close()
これで山中一郎さんのデータが削除されました。








コメント