ここでは、DataFrameの列や行、そしてその要素にアクセスする方法を解説します。
なお、慣例に従って以下のようにpandasをインポートしているものとして進めていきます。
import pandas as pd
サンプルデータ
サンプルデータとして以下のデータを用います。
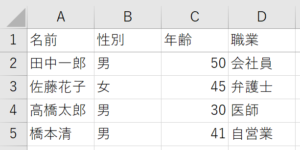
以下のようにURLを指定して、DataFrameとして取得できます。
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
添え字で直接指定する (列全体 / 行全体の指定)
列の指定
DataFrameの添え字[]に文字列や数値、もしくはそのリストで指定すると列ラベルの指定と解釈されて、列全体が返されます。
添え字に列ラベルを単独で指定すると、その列がSeriesとして返されます。
print(df['名前'])
※ df : サンプルデータ
0 田中一郎 1 佐藤花子 2 高橋太郎 3 橋本清 Name: 名前, dtype: object
添え字に列ラベルをリストで指定すると、その列がDataFrameとして返されます。
print(df[['名前', '年齢']])
※ df : サンプルデータ
名前 年齢 0 田中一郎 50 1 佐藤花子 45 2 高橋太郎 30 3 橋本清 41
行の指定
添え字にスライスで指定すると行の指定と解釈されて、該当する行全体がDataFrameとして返されます。
print(df[2:4])
※ df : サンプルデータ
名前 性別 年齢 職業 2 高橋太郎 男 30 医師 3 橋本清 男 41 自営業
列名の属性として指定する (列全体の指定)
列名を属性と同様に扱い、DataFrame名の後に「.」に続けて指定することができます。
print(df.名前)
※ df : サンプルデータ
0 田中一郎 1 佐藤花子 2 高橋太郎 3 橋本清 Name: 名前, dtype: object
上記のように、テストした環境では列ラベルを日本語で指定しても正しく列を抽出できていましたが、プログラム内に日本語が混じるのはバグの原因になり得るので、あまり推奨できません。列名が日本語である場合は、添え字で指定した方が無難だと思います。
また、列名にスペースが入る場合はこの方法は使えませんのでご注意ください。
loc属性で指定する
行ラベル・列ラベルで指定する
loc属性は行ラベル・列ラベルを用いて、行と列を指定してその要素を取り出すためのものです。loc属性の添え字の1番目で行ラベル(=第1軸)、2番目で列ラベル(=第2軸)を指定します。
なお、行ラベルを設定していない場合はデフォルトで0, 1, … の数値型のインデックスが行ラベルとして割り振られています。
print(df.loc[1, '名前'])
※ df : サンプルデータ
佐藤花子
この時のデータ型は格納されているオブジェクトそのものになります。
行・列のどちらか一方をリスト(スライス)で指定する
行・列のどちらかをリストで指定することで、複数の行・列をまとめてSeriesとして取得することができます。
print(df.loc[[1,3],'名前'])
※ df : サンプルデータ
1 佐藤花子 3 橋本清 Name: 名前, dtype: object
行ラベル・列ラベルをスライスで指定することも可能です。
print(df.loc[1:4,'名前'])
※ df : サンプルデータ
1 佐藤花子 2 高橋太郎 3 橋本清 Name: 名前, dtype: object
print(df.loc[1,'名前':'年齢'])
※ df : サンプルデータ
名前 佐藤花子 性別 女 年齢 45 Name: 1, dtype: object
行ラベル・列ラベルの指定はスライスで以下のようにすると、行全体・列全体を指定することができます。
- df.loc[‘行ラベル1’, :] → 指定した行のすべての列が抽出される
- df.loc[‘行ラベル1’] と省略可能
- df.loc[:, ‘列ラベル1’] →指定した列のすべての行が抽出される
print(df.loc[1]) # df.loc[1, :]と同じ
※ df : サンプルデータ
名前 佐藤花子 性別 女 年齢 45 職業 弁護士 Name: 1, dtype: object
行・列の両方ともリスト(スライス)で指定する
行・列の両方をリスト(スライス)で指定することで、その行・列で指定されたデータによるサブセットのDataFrameが取得できます。
print(df.loc[1:4,['名前', '年齢']])
※ df : サンプルデータ
名前 年齢 1 佐藤花子 45 2 高橋太郎 30 3 橋本清 41
まとめ
まとめると次のように、loc属性は[]内に行ラベルと列ラベルを指定することができます。

- 行ラベル・列ラベルで指定する → DataFrameのデータそのものが得られる
- 行・列のどちらか一方をリスト(スライス)で指定する → Seriesが得られる
- 行・列の両方ともリスト(スライス)で指定する → DataFrameが得られる
iloc属性で指定する
loc属性が行ラベル・列ラベルで指定していたのに対して、iloc属性は行番号・列番号で指定するようになっただけのもので、使い方はloc属性と同じです。
行番号・列番号で指定する
print(df.iloc[1, 0])
※ df : サンプルデータ
佐藤花子
行・列のどちらか一方をリスト(スライス)で指定する
行・列のどちらかをリストで指定することで、複数の行・列をまとめてSeriesとして取得することができます。
print(df.iloc[[1,3],0])
※ df : サンプルデータ
1 佐藤花子 3 橋本清 Name: 名前, dtype: object
行番号・列番号の指定はスライスで以下のようにすると、行全体・列全体を指定することができます。
- df.iloc[行番号1, :] → 指定した行のすべての列が抽出される
- df.iloc[行番号1] と省略可能
- df.iloc[:, 列番号1] →指定した列のすべての行が抽出される
print(df.iloc[1]) # df.iloc[1, :]と同じ
※ df : サンプルデータ
名前 佐藤花子 性別 女 年齢 45 職業 弁護士 Name: 1, dtype: object
行・列の両方ともリスト(スライス)で指定する
行・列の両方をリスト(スライス)で指定することで、その行・列で指定されたデータによるサブセットのDataFrameが取得できます。
print(df.iloc[1:4,[0,2]])
※ df : サンプルデータ
名前 年齢 1 佐藤花子 45 2 高橋太郎 30 3 橋本清 41
まとめ
まとめると次のように、iloc属性は[]内に行番号と列番号を指定することができます。

- 行番号・列番号で指定する → DataFrameのデータそのものが得られる
- 行・列のどちらか一方をリスト(スライス)で指定する → Seriesが得られる
- 行・列の両方ともリスト(スライス)で指定する → DataFrameが得られる








コメント