Excelは多くの方が使い慣れたソフトウェアであり、簡易的なデータベースとしても使えることから、データ解析のデータがExcelファイルで保存されていることがよくあります。ここでは、ExcelファイルのデータをDataFrameに読み込む方法と、DataFrameからExcelファイルへ出力する方法を説明していきます。
開発環境
- Python 3.7.7
- Pandas 1.0.3
pandasからのExcelファイルへのアクセス
pandasで、ExcelファイルからDataFrameに読み込む際はread_excel関数を、DataFrameからExcelファイルへ出力する際はDataFrameのto_excelメソッドを用います。なお、Excelファイルの入出力には、内部的にxlrdライブラリ / xlwtライブラリとOpenPyXLライブラリを使用しているのであらかじめインストールしておく必要があります(condaでpandasをインストールした場合は、これらの依存ライブラリも同時にインストールされるので、追加でインストールする必要はありません)。
※ 以前はxlrdライブラリがデフォルトでしたが、xlrd 2.0.0以降は.xlsx形式に対応しなくなったために、現在はPandasのデフォルトがOpenPyXLに変更されています。
ExcelファイルからDataFrameへの読み込み
サンプルデータ
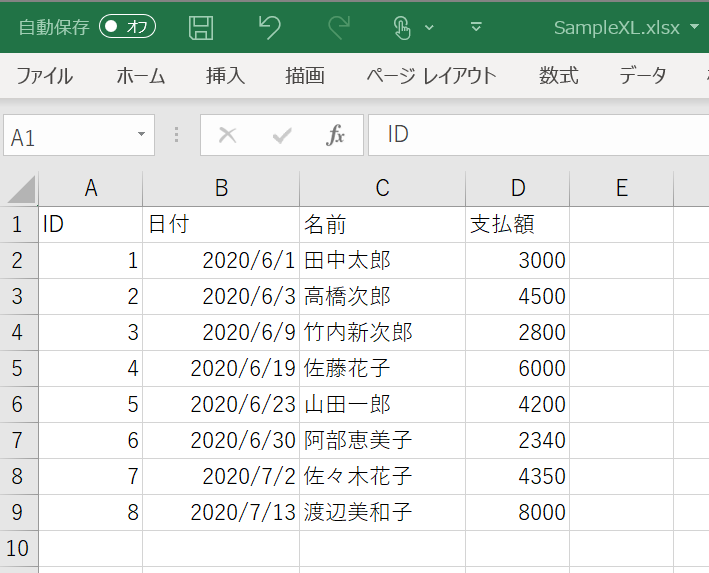
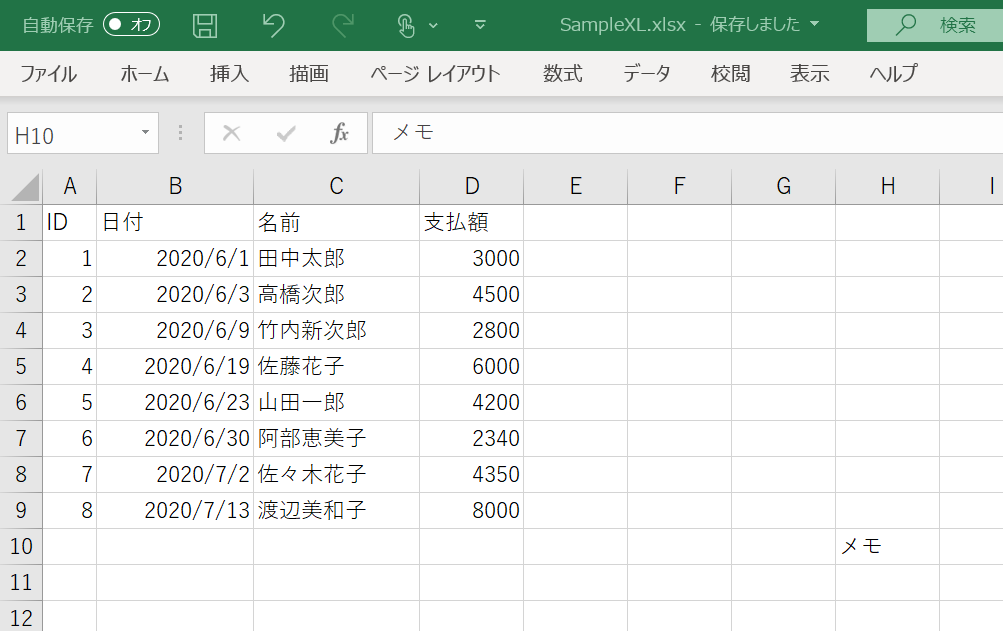
ここでは、サンプルデータとして、以下のExcelファイルを「C:\BioTech-Lab\SampleXL.xlsx」に保存して、それを読み込んでみましょう。
基本的な読み込み方
Excelファイルの読み込みはpandasのread_excel関数を用います。第一引数にファイルパスもしくはURLのみを指定すると、そのExcelファイルの1番最初のSheetが読み込まれます。その際にデフォルトでは1行目がヘッダー(列ラベル)として認識され、行インデックスは自動で割り振られます。
import pandas as pd
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx")
print(df)
ID 日付 名前 支払額 0 1 2020-06-01 田中太郎 3000 1 2 2020-06-03 高橋次郎 4500 2 3 2020-06-09 竹内新次郎 2800 3 4 2020-06-19 佐藤花子 6000 4 5 2020-06-23 山田一郎 4200 5 6 2020-06-30 阿部恵美子 2340 6 7 2020-07-02 佐々木花子 4350 7 8 2020-07-13 渡辺美和子 8000
Sheetを指定して読み込む
read_excel関数のsheet_name引数に読み込むSheetの番号か名前を指定することで、Sheetを指定して読み込むことができます。なお、sheet_name引数はリストでも指定可能なので、複数のSheetを指定することができます。
Sheetの番号で指定する場合は一番左のSheetが0で、左から順番に0, 1, 2, … となっています。(デフォルトではsheet_name=0となっています)
例えば、Sheet2を指定するには次のようにします。
# Sheet番号で指定する
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx", sheet_name=1)
# Sheet名で指定する
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx", sheet_name='Sheet2')
Sheet番号で指定する場合はSheet2は左から2番目なので番号は1となり、Sheet名で指定する場合はそのまま’Sheet2’を指定します。
列ラベル・行インデックスを指定して読み込む
列ラベルの指定
デフォルトではExcelデータの1行目がヘッダー(列ラベル)として読み取られるので、ヘッダーがない場合はheader引数にNoneを指定します。
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx", header=None)
列ラベルの名前は、Excelファイルのヘッダーがそのまま使われますが、names引数で明示的に設定することもできます。
import pandas as pd
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx", names=['A', 'B', 'C', 'D'])
print(df)
A B C D 0 1 2020-06-01 田中太郎 3000 1 2 2020-06-03 高橋次郎 4500 2 3 2020-06-09 竹内新次郎 2800 3 4 2020-06-19 佐藤花子 6000 4 5 2020-06-23 山田一郎 4200 5 6 2020-06-30 阿部恵美子 2340 6 7 2020-07-02 佐々木花子 4350 7 8 2020-07-13 渡辺美和子 8000
行インデックスの指定
index_col引数に列番号を指定すると、その列が行インデックスとして扱われます。デフォルトではNoneとなっていますが、例えば次のように1列目を行インデックスとして指定してみましょう。
import pandas as pd
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx", index_col=0)
print(df)
日付 名前 支払額 ID 1 2020-06-01 田中太郎 3000 2 2020-06-03 高橋次郎 4500 3 2020-06-09 竹内新次郎 2800 4 2020-06-19 佐藤花子 6000 5 2020-06-23 山田一郎 4200 6 2020-06-30 阿部恵美子 2340 7 2020-07-02 佐々木花子 4350 8 2020-07-13 渡辺美和子 8000
これでExcelファイルの1列目が行インデックスとして設定されました。
マルチインデックスの指定
index_col引数やheader引数に複数行を指定することもできます。この場合、同じ行インデックスや列ラベルは統合されマルチインデックスとして読み込まれます。なお、Excel上で「セルを結合して中央揃え」をしていても、正しく処理されます。
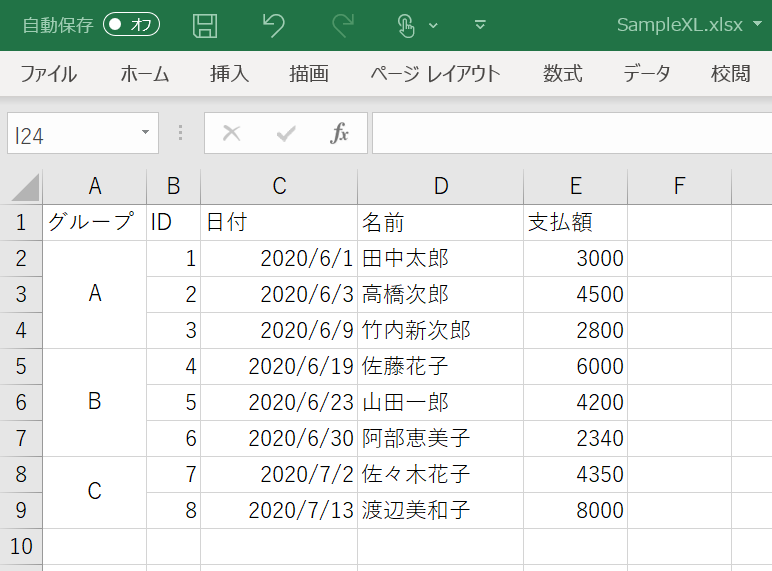
例えば次のようなデータを読み取ってみましょう。
import pandas as pd
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx", index_col=[0, 1])
print(df)
日付 名前 支払額
グループ ID
A 1 2020-06-01 田中太郎 3000
2 2020-06-03 高橋次郎 4500
3 2020-06-09 竹内新次郎 2800
B 4 2020-06-19 佐藤花子 6000
5 2020-06-23 山田一郎 4200
6 2020-06-30 阿部恵美子 2340
C 7 2020-07-02 佐々木花子 4350
8 2020-07-13 渡辺美和子 8000
このように、行インデックスに複数の列を指定して、マルチインデックスとして読み込まれていることが分かります。
なお、マルチインデックスについては以下の記事をご覧ください。

補足事項
read_excel関数で読み取られるのは、ExcelのSheetのデータのある部分だけですが、グラフやテキストボックスなどセル部分以外のデータは無視されます。したがって、次のようなExcelファイルは問題なく読み込むことができます。
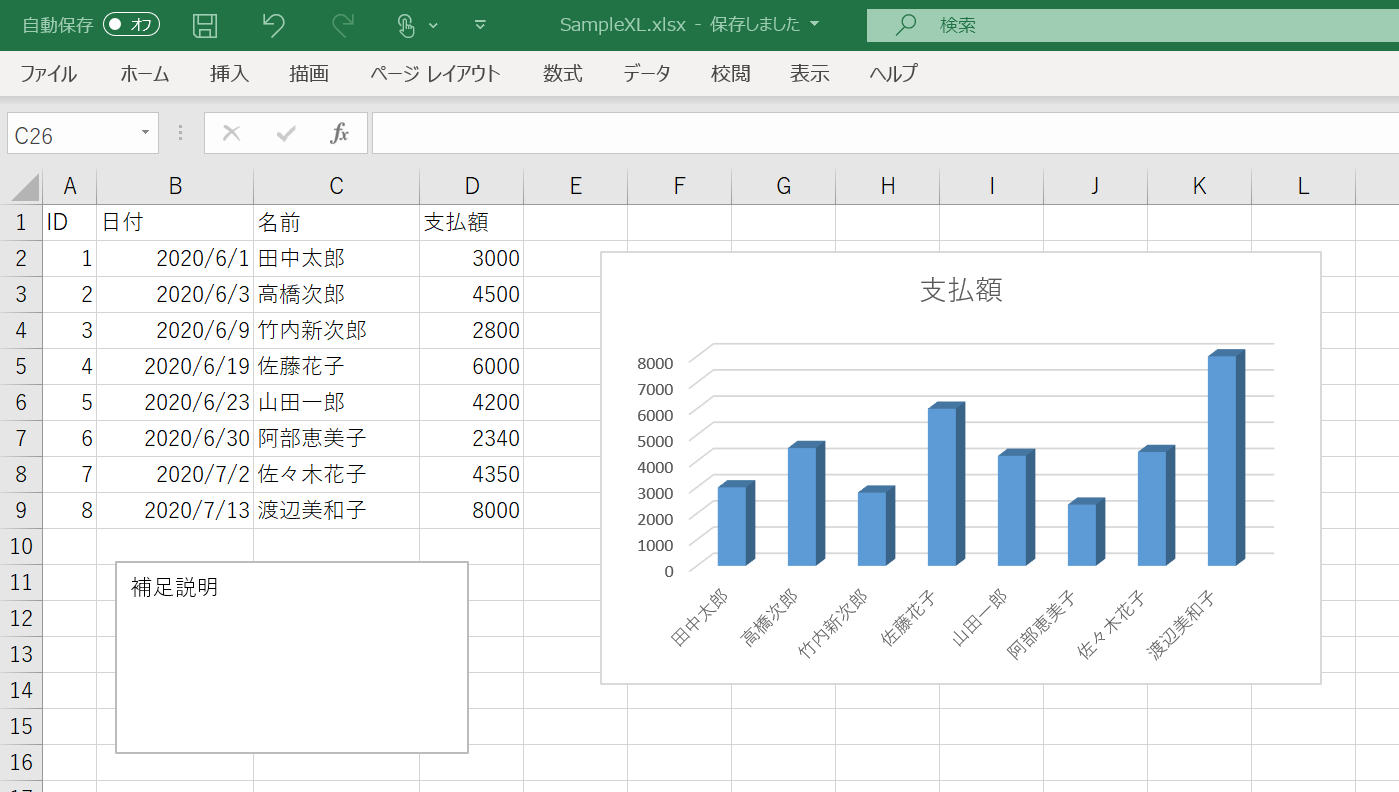
しかし、例えば次のようにセルに余分なデータが含まれている場合は、その範囲までのデータが読み取られてしまうので注意してください。
import pandas as pd
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx")
print(df)
ID 日付 名前 支払額 Unnamed: 4 Unnamed: 5 Unnamed: 6 Unnamed: 7 0 1.0 2020-06-01 田中太郎 3000.0 NaN NaN NaN NaN 1 2.0 2020-06-03 高橋次郎 4500.0 NaN NaN NaN NaN 2 3.0 2020-06-09 竹内新次郎 2800.0 NaN NaN NaN NaN 3 4.0 2020-06-19 佐藤花子 6000.0 NaN NaN NaN NaN 4 5.0 2020-06-23 山田一郎 4200.0 NaN NaN NaN NaN 5 6.0 2020-06-30 阿部恵美子 2340.0 NaN NaN NaN NaN 6 7.0 2020-07-02 佐々木花子 4350.0 NaN NaN NaN NaN 7 8.0 2020-07-13 渡辺美和子 8000.0 NaN NaN NaN NaN 8 NaN NaT NaN NaN NaN NaN NaN メモ
DataFrameからExcelファイルへの出力
DataFrameからExcelファイルへ出力する際は、DataFrameクラスのto_excelメソッドを用います。
先ほど読み込んだサンプルのExcelデータをそのまま出力してみましょう。
import pandas as pd
df = pd.read_excel(r"C:\BioTech-Lab\SampleXL.xlsx")
df.to_excel(r"C:\BioTech-Lab\SampleXL-2.xlsx")
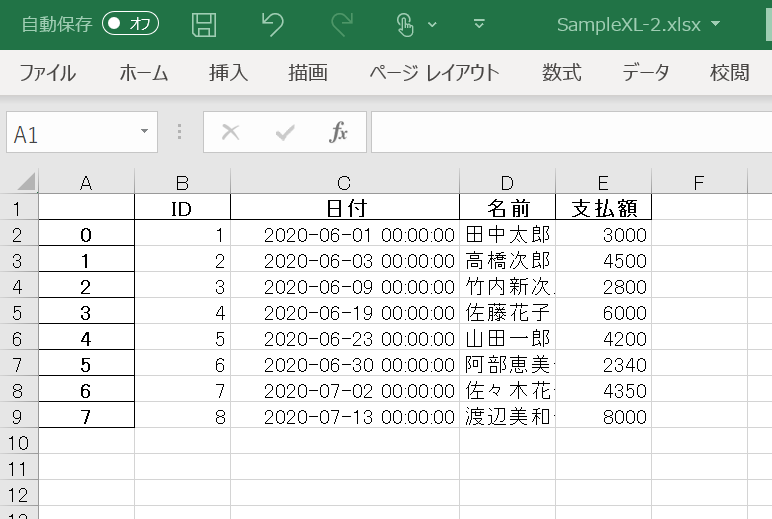
このようにExcelファイルとして出力されました。デフォルトで、行インデックス・列ラベル部分は罫線で囲まれるようになっているようです。
出力するSheet名はsheet_name引数で設定でき、デフォルトでSheet1となっています。
また、行インデックスや列ラベルにマルチインデックスが設定されている場合は、ここで出力するExcelファイルでも「セルを結合して中央揃え」にして反映させてくれます。








コメント