ここでは、DataFrameへの行・列の追加方法について解説します。なお、DataFrameの結合同士を結合する方法については「DataFrameの結合」の記事をご覧ください。
開発環境
- pandas 1.2.1
- Python 3.7.9

サンプルデータ
サンプルデータとして以下のデータを用います。
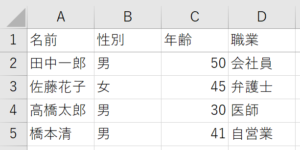
以下のようにURLを指定して、DataFrameとして取得できます。
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
DataFrameの行を追加する (appendメソッド)
DataFrameに行を追加するには、appendメソッドを用います。
appendメソッドで追加する項目としては、DataFrame、Series、辞書型が指定可能です。
DataFrameに別のDataFrameの行を追加する
以下の例ではサンプルデータにDataFrameで行を追加します。
import pandas as pd
df_sample = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
df = pd.DataFrame([['鈴木次郎', '男', 23, '学生'],
['渡辺秋子', '女', 33, '看護師']],
columns=['名前', '性別', '年齢', '職業'])
df_new = df_sample.append(df)
print(df_new)
名前 性別 年齢 職業 0 田中一郎 男 50 会社員 1 佐藤花子 女 45 弁護士 2 高橋太郎 男 30 医師 3 橋本清 男 41 自営業 0 鈴木次郎 男 23 学生 1 渡辺秋子 女 33 看護師
今の例ではignore_indexはデフォルトのままFalseだったので、元のDataFrameの行番号がそのまま継承されています。しかし、これでは行番号が重複してしまっているので、ignore_indexをTrueにしてみます。
import pandas as pd
df_sample = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
df = pd.DataFrame([['鈴木次郎', '男', 23, '学生'],
['渡辺秋子', '女', 33, '看護師']],
columns=['名前', '性別', '年齢', '職業'])
df_new = df_sample.append(df, ignore_index=True)
print(df_new)
名前 性別 年齢 職業 0 田中一郎 男 50 会社員 1 佐藤花子 女 45 弁護士 2 高橋太郎 男 30 医師 3 橋本清 男 41 自営業 4 鈴木次郎 男 23 学生 5 渡辺秋子 女 33 看護師
これで新たな行番号を振りなおすことができました。
なお、元のDataFrameと新たに追加するDataFrameとで列ラベルが一致しない場合は、次のよう新たな列ラベルが生成されてしまいます。
import pandas as pd
df_sample = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
df = pd.DataFrame([['鈴木次郎', '男', 23, '学生'],
['渡辺秋子', '女', 33, '看護師']])
df_new = df_sample.append(df)
print(df_new)
0 1 2 3 名前 年齢 性別 職業 0 NaN NaN NaN NaN 田中一郎 50.0 男 会社員 1 NaN NaN NaN NaN 佐藤花子 45.0 女 弁護士 2 NaN NaN NaN NaN 高橋太郎 30.0 男 医師 3 NaN NaN NaN NaN 橋本清 41.0 男 自営業 0 鈴木次郎 男 23.0 学生 NaN NaN NaN NaN 1 渡辺秋子 女 33.0 看護師 NaN NaN NaN NaN
DataFrameにSeries / 辞書で行を追加する
Seriesで行を追加する場合は次のようにします。
import pandas as pd
df_sample = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
data = pd.Series({'名前' : '鈴木次郎', '性別' : '男', '年齢' : 23, '職業' : '学生'})
df_new = df_sample.append(data, ignore_index=True)
辞書で行を追加する場合は次のようにします。
import pandas as pd
df_sample = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
data = {'名前' : '鈴木次郎', '性別' : '男', '年齢' : 23, '職業' : '学生'}
df_new = df_sample.append(data, ignore_index=True)
DataFrameにリストで行を追加する
appendメソッドで追加できる要素は「DataFrame、Series、辞書型」が基本ですが、リストで行を追加することもできるようです。この場合は次のサンプルのようにリストを入れ子にした2重のリストにする必要があります。
import pandas as pd
df_sample = pd.DataFrame([['鈴木次郎', '男', 23, '学生'],
['渡辺秋子', '女', 33, '看護師']])
data = ['高梨五郎', '男', 42, '会社役員']
df_new = df_sample.append([data], ignore_index=True)
print(df_new)
0 1 2 3 0 鈴木次郎 男 23 学生 1 渡辺秋子 女 33 看護師 2 高梨五郎 男 42 会社役員
この場合はappendメソッドで指定するリストの列ラベルは「0, 1, 2, 3, …」となります。そのため、この例のようにDataFrameの列ラベルを指定していない場合は問題ないのですが、次のようにDataFrameの列ラベルを指定してある場合は新たな列ラベルが作成されてしまいます。
import pandas as pd
df_sample = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
data = ['高梨五郎', '男', 42, '会社役員']
df_new = df_sample.append([data], ignore_index=True)
print(df_new)
0 1 2 3 名前 年齢 性別 職業 0 NaN NaN NaN NaN 田中一郎 50.0 男 会社員 1 NaN NaN NaN NaN 佐藤花子 45.0 女 弁護士 2 NaN NaN NaN NaN 高橋太郎 30.0 男 医師 3 NaN NaN NaN NaN 橋本清 41.0 男 自営業 4 高梨五郎 男 42.0 会社役員 NaN NaN NaN NaN
このようにappendメソッドにリストで行を追加することも可能ですが、想定外の結果になってしまう場合もあるので注意が必要です。
DataFrameの列を追加する
DataFrameに添え字[]で新たな列ラベルを指定し、リストでその項目を指定することで、列を追加することができます。
例えば、「住所」という列を追加してみます。
import pandas as pd
df_sample = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
df_sample['住所'] = ['東京都', '埼玉県', '大阪府', '京都府']
print(df_sample)
名前 性別 年齢 職業 住所 0 田中一郎 男 50 会社員 東京都 1 佐藤花子 女 45 弁護士 埼玉県 2 高橋太郎 男 30 医師 大阪府 3 橋本清 男 41 自営業 京都府








コメント