Pythonのpandasモジュールを用いて、2つのDataFrameを結合する方法を説明します。
開発環境
- pandas 1.2.1
- Python 3.7.9
テーブルの結合方法 – 外部結合と内部結合
データベースのテーブルの結合方法には、結合するテーブルのキーの取り扱い方によって外部結合と内部結合とがあります。PythonのDataFrameの結合でも同様の考え方が必要になってくるので、まずはここで外部結合と内部結合について説明します。
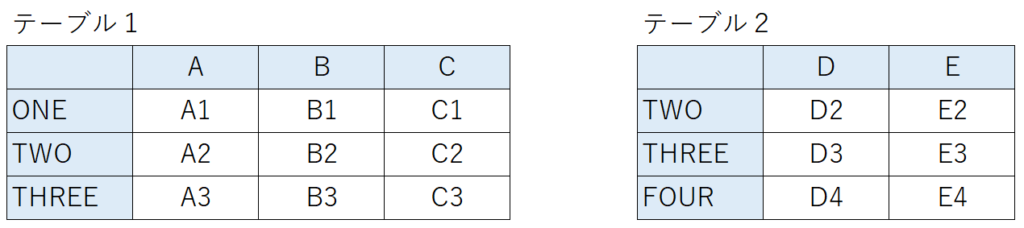
次の2つのテーブルを結合する場合を考えてみましょう。
外部結合
基準となるテーブルのキーを新しく結合したテーブルのキーとする結合方法です。基準となるテーブルの取り方によって「完全外部結合」「左外部結合」「右外部結合」の3種類があります。
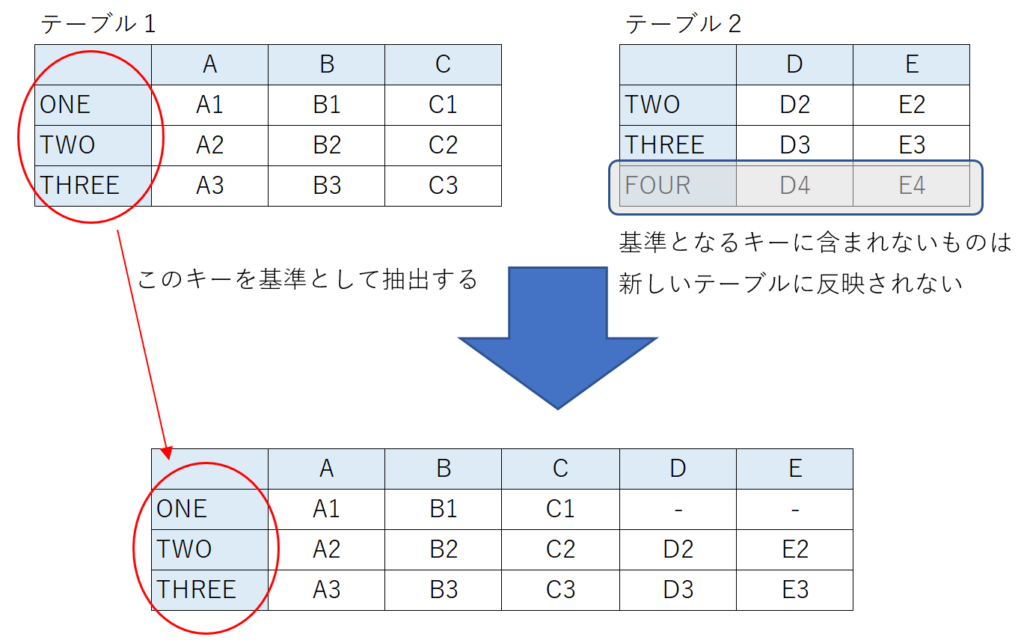
左外部結合
左外部結合では結合するテーブルのうち左側のテーブルを基準とします。左側のテーブルのキーを新しいテーブルのキーとして、右側のテーブルのキーで左側のテーブルに含まれないものは無視されます。
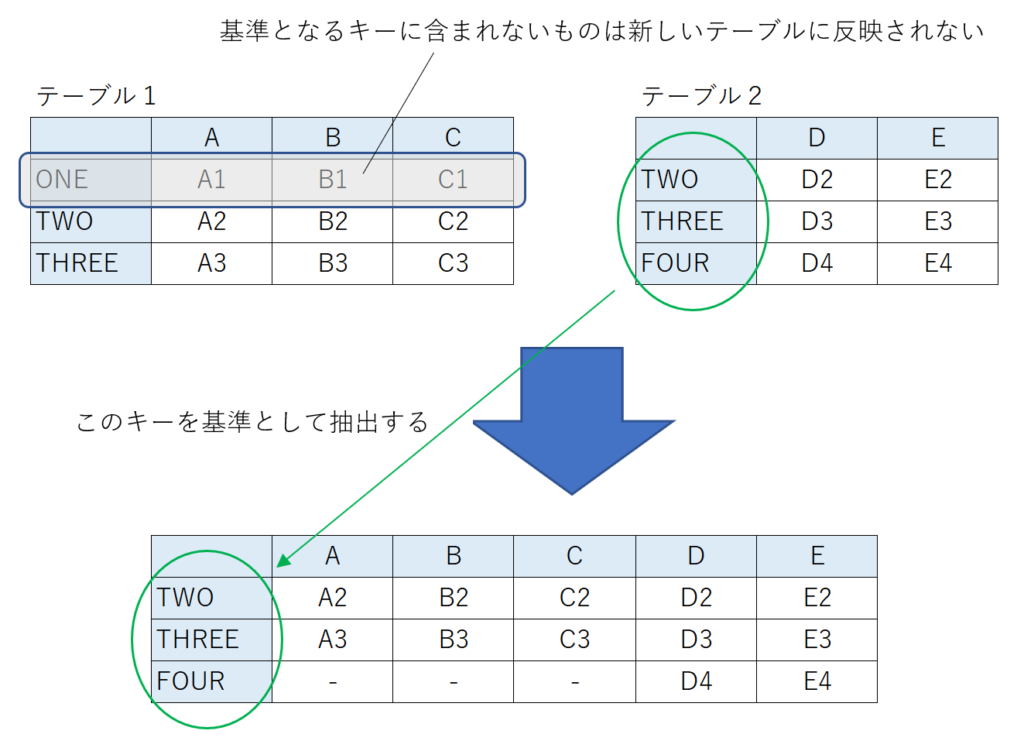
右外部結合
右外部結合では結合するテーブルのうち右側のテーブルを基準とします。右側のテーブルのキーを新しいテーブルのキーとして、左側のテーブルのキーで右側のテーブルに含まれないものは無視されます。
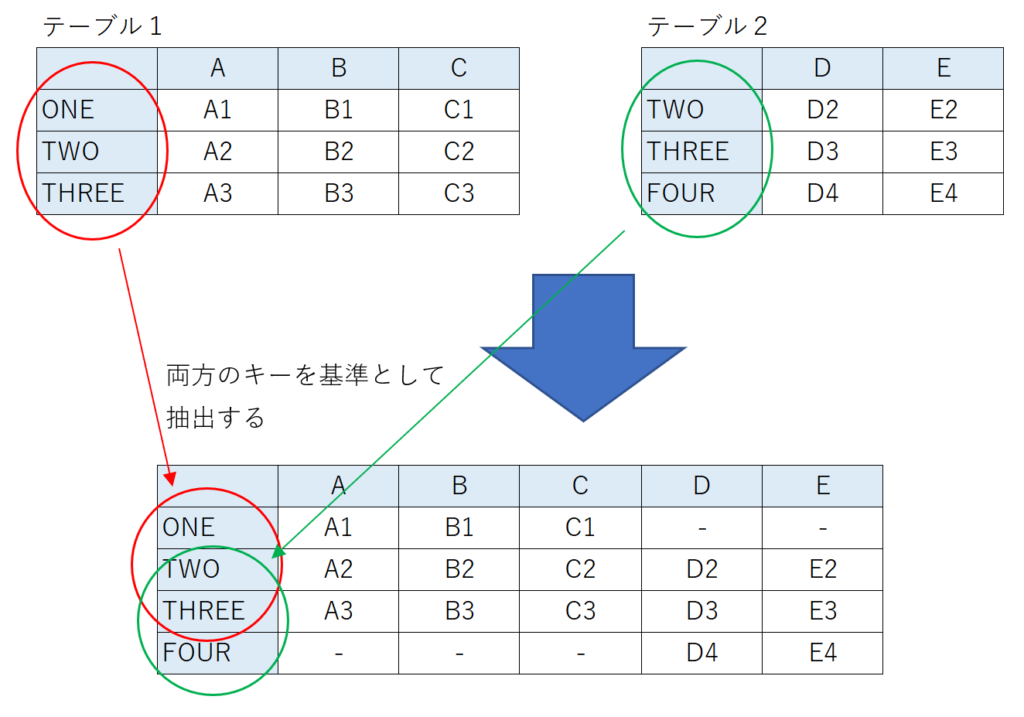
完全外部結合
完全外部結合では結合するテーブルの両方のキーを基準として新しいテーブルを作成します。この場合はすべてのキーが新しいテーブルに反映され、無視されるキーはありません。
なお、単純に外部結合といった場合は完全外部結合を示していることがあります。
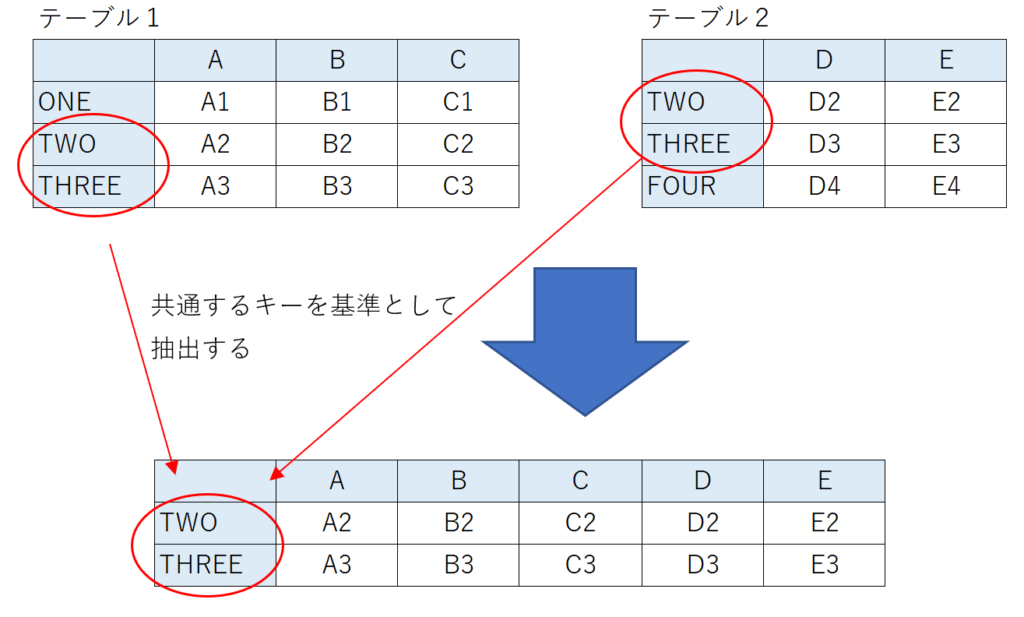
内部結合
結合する2つのテーブルの共通するキーのみを抽出して新しいテーブルを作成する結合方法です。どちらか一方のテーブルにしか存在しないキーは無視されます。
DataFrameを結合する関数・メソッドの特徴
DataFrameを結合するための関数・メソッドは、concat関数、mergeメソッド、joinメソッドがあります。ここではそれぞれの関数・メソッドの使い方を説明して、その関数・メソッドの使い分けについて説明していきます。
それでは、以下のテーブルをインデックス列をキーとして、完全外部結合することを考えていきましょう。
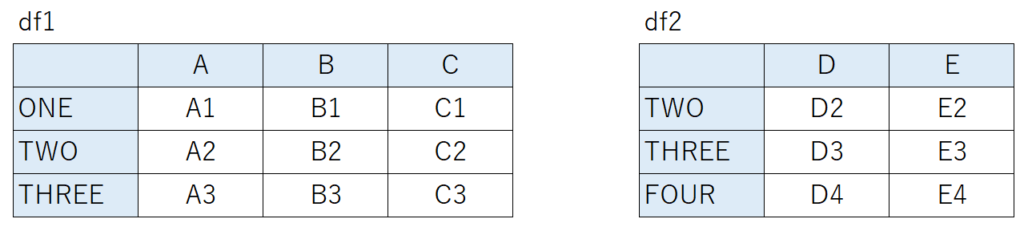
concat関数
concat関数の引数にDataFrameのリストを与えることで、そのDataFrameのインデックスをもとに横方向に結合します。
import pandas as pd
df1 = pd.DataFrame({'A': ['A1', 'A2', 'A3'],
'B': ['B1', 'B2', 'B3'],
'C': ['C1', 'C2', 'C3']},
index=['ONE', 'TWO', 'THREE'])
df2 = pd.DataFrame({'D': ['D2', 'D3', 'D4'],
'E': ['E2', 'E3', 'E4']},
index=['TWO', 'THREE', 'FOUR'])
df_concat = pd.concat([df1, df2], axis='columns')
print(df_concat)
A B C D E ONE A1 B1 C1 NaN NaN TWO A2 B2 C2 D2 E2 THREE A3 B3 C3 D3 E3 FOUR NaN NaN NaN D4 E4
インデックスが設定されていない場合は、双方の1行目、2行目、3行目、…同士が結合されます。なお、列をもとに縦方向結合する場合はaxis引数を’index’に設定します(デフォルトはaxis=’index’で縦方向の結合)。また、結合方法についてはjoin引数(‘outer’, ‘inner’)で「外部結合」もしくは「内部結合」を指定します。
mergeメソッド
DataFramクラスのmergeメソッドを用いてDataFramを結合する方法です。結合方法やキーとする列を指定して、DataFrameを横方向に結合します。
import pandas as pd
df1 = pd.DataFrame({'A': ['A1', 'A2', 'A3'],
'B': ['B1', 'B2', 'B3'],
'C': ['C1', 'C2', 'C3']},
index=['ONE', 'TWO', 'THREE'])
df2 = pd.DataFrame({'D': ['D2', 'D3', 'D4'],
'E': ['E2', 'E3', 'E4']},
index=['TWO', 'THREE', 'FOUR'])
df_merge = df1.merge(df2, left_index=True, right_index=True, how='outer')
print(df_merge)
A B C D E FOUR NaN NaN NaN D4 E4 ONE A1 B1 C1 NaN NaN THREE A3 B3 C3 D3 E3 TWO A2 B2 ZZ ZZ E2
mergeメソッドの特徴は左右のDataFramでどの列をキーにするのかを細かく指定できる点です。DataFrameにインデックス(行ラベル)が設定されていて、それをキーにするには左右それぞれのDataFramで指定します(right_index=True / left_index=True)。インデックスがキーに指定されていない場合(デフォルトではright_index=False / left_index=False)は、両方のDataFrameに共通する名前の列をキーとして結合されます。共通する名前の列が複数ある場合は、そのすべての列がキーとして処理されます。また、明示的にキーを指定する場合はon引数で指定します。さらに、左右で異なる名前の列をキーとして指定するためにはright_on, left_on引数でそれぞれ指定できます。ちなみに、共通する名前の列があっても、right_index=True などのようにインデックスが指定されている場合は、インデックスが優先的にキーとして割り当てられます。
DataFrameの結合方法はhow引数で指定します(‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’)。
次の例ではインデックスは指定せずに、right_on, left_on引数でキーを指定しています。なお、この例ではDataFramのデータの一部を先ほどの例とは差し替えています。
import pandas as pd
df1 = pd.DataFrame({'A': ['A1', 'A2', 'A3'],
'B': ['B1', 'B2', 'B3'],
'C': ['C1', 'ZZ', 'C3']},
index=['ONE', 'TWO', 'THREE'])
df2 = pd.DataFrame({'D': ['ZZ', 'D3', 'D4'],
'E': ['E2', 'E3', 'E4']},
index=['TWO', 'THREE', 'FOUR'])
df_merge = df1.merge(df2, left_on='C', right_on='D', how='outer')
print(df_merge)
A B C D E 0 A1 B1 C1 NaN NaN 1 A2 B2 ZZ ZZ E2 2 A3 B3 C3 NaN NaN 3 NaN NaN NaN D3 E3 4 NaN NaN NaN D4 E4
left_on=’C’, right_on=’D’ と指定することで、左側はC列、右側はD列がキーとしてDataFramが結合されます。新しく生成されたDataFramでもC列・D列はそのまま残っていますが、C列・D列のデータが同じ(ZZ)ものは1行にまとめられていることが分かります。
joinメソッド
joinメソッドでは、デフォルトでインデックス列をキーとした左外部結合を行います。結合方法はhow引数で指定してください(‘left’, ‘right’, ‘outer’, ‘inner’)。右側に来るDataFrame(引数に指定するDataFrame)はインデックス列以外もキーにできますが、左側のDataFrame(メソッドを呼び出すDataFrame)ではインデックス列のみしかキーに指定できません。そのため両方ともインデックス列以外をキーにして結合するためにはmergeメソッドを用いる必要があります。
import pandas as pd
df1 = pd.DataFrame({'A': ['A1', 'A2', 'A3'],
'B': ['B1', 'B2', 'B3'],
'C': ['C1', 'C2', 'C3']},
index=['ONE', 'TWO', 'THREE'])
df2 = pd.DataFrame({'D': ['C2', 'D3', 'D4'],
'E': ['E2', 'E3', 'E4']},
index=['TWO', 'THREE', 'FOUR'])
df_join = df1.join(df2, how='outer')
print(df_join)
A B C D E ONE A1 B1 C1 NaN NaN TWO A2 B2 C2 C2 E2 THREE A3 B3 C3 D3 E3
DataFrameを結合する関数・メソッドの使い分け
concat関数やmergeメソッド、joinメソッドはどれを用いても同様なことが実現可能ではあるのですが、それぞれの関数・メソッドによってシンプルに処理を書けたり、煩雑になったりなどという得意・不得意があります。コードの可読性を向上させバグを減らすためにはシンプルな記述を心がけたいところであり、その観点からのDataFrameの結合処理の使い分けを考えてみましょう。
インデックス列をキーとしてDataFrameを結合する場合
すでにDataFrameにインデックス列(行ラベル)が設定されていて、それをキーとして結合する場合です。この場合はconcat関数もしくはjoinメソッドを用いるとシンプルにコードを書くことができます。例えばDataFrame_AとDataFrame_Bをインデックス列をキーとして完全外部結合を行う処理はjoinメソッドを用いると次のようになります。
# concat関数で結合を行う
df_concat = pd.concat([DataFrame_A, DataFrame_B], axis='columns')
# joinメソッドで結合を行う
df_join = DataFrame_A.join(DataFrame_B, how='outer')
同様の処理をmergeメソッドを用いて行うと次のようになります。
# mergeメソッドで結合を行う
df_merge = DataFrame_A.merge(DataFrame_B, left_index=True, right_index=True, how='outer')
mergeメソッドでも同じことはできるのですが、デフォルトではインデックス列がキーになっていないので、わざわざ指定しないといけないのはやや煩雑になってしまいます。
インデックス列以外をキーとしてDataFrameを結合する場合
先ほどとは逆にこの場合はmergeメソッドが使いやすいです。mergeメソッドではデフォルトでインデックス列以外をキーとするようになっているので、一番シンプルにコーディングできるように思います。例えばDataFrame_AとDataFrame_Bとを共通する名前の列(インデックス列以外)をキーとして完全外部結合を行う処理はmergeメソッドを用いると次のようになります。
# mergeメソッドで結合を行う
df_merge = DataFrame_A.merge(DataFrame_B, how='outer')
なお、インデックス列がもともと設定されている場合は、この処理を行うとインデックス列は新たに振りなおされます。
concat関数ではインデックス列以外をキーとすることはできず、joinメソッドでも左側のDataFrameはインデックス列をキーとする必要があります。
3つ以上のDataFrameを結合する場合
concat関数とjoinメソッドでは引数にDataFrameのリストを指定することが可能ですが、mergeメソッドでは引数に指定できるDataFrameは1つのみです。例えばDataFrame_A、DataFrame_B、DataFrame_Cをインデックス列をキーとして結合する場合は次のようになります。
# concat関数で結合を行う
df_concat = pd.concat([DataFrame_A, DataFrame_B, DataFrame_C], axis='columns')
# joinメソッドで結合を行う
df_join = DataFrame_A.join([DataFrame_B, DataFrame_C], how='outer')
縦方向にDataFrameを結合する場合
今まではキーとして設定した列をもとに新たな列としてDataFrameを付け加えて横方向に結合していました。結合方法にはこのほかにもDataFrameを新たな行として使加えて、縦方向に結合する方法もあります。これができるのはconcat関数のみです。concat関数ではこの縦方向の結合がデフォルトとなっています。
結合する列名に重複がある場合の処理の違い
列名に重複がある場合の扱い方はconcat関数、mergeメソッド、joinメソッドで異なります。
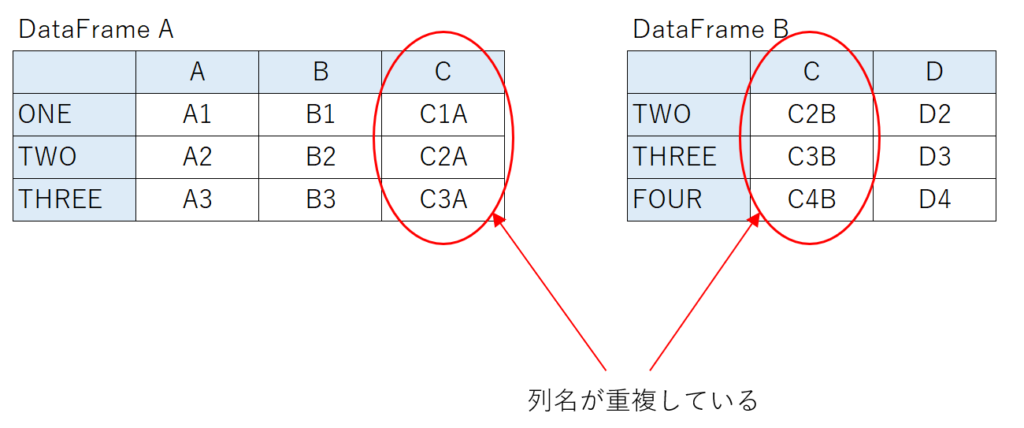
この2つのDataFrameをインデックス列をキーとして完全外部結合した処理結果を見てみましょう。
import pandas as pd
DataFrame_A = pd.DataFrame({'A': ['A1', 'A2', 'A3'],
'B': ['B1', 'B2', 'B3'],
'C': ['C1A', 'C2A', 'C3A']},
index=['ONE', 'TWO', 'THREE'])
DataFrame_B = pd.DataFrame({'C': ['C2B', 'D3B', 'D4B'],
'D': ['C2', 'D3', 'D4']},
index=['TWO', 'THREE', 'FOUR'])
print('------------concat関数------------')
df_concat = pd.concat([DataFrame_A, DataFrame_B], axis='columns')
print(df_concat)
print('------------mergeメソッド------------')
df_merge = DataFrame_A.merge(DataFrame_B, left_index=True, right_index=True, how='outer')
print(df_merge)
print('------------joinメソッド------------')
df_join = DataFrame_A.join(DataFrame_B, how='outer')
print(df_join)
------------concat関数------------
A B C C D
ONE A1 B1 C1A NaN NaN
TWO A2 B2 C2A C2B C2
THREE A3 B3 C3A D3B D3
FOUR NaN NaN NaN D4B D4
------------mergeメソッド------------
A B C_x C_y D
FOUR NaN NaN NaN D4B D4
ONE A1 B1 C1A NaN NaN
THREE A3 B3 C3A D3B D3
TWO A2 B2 C2A C2B C2
------------joinメソッド------------
実はこのコードを実行するとjoinメソッドの処理で以下のエラー(columns overlap but no suffix specified: Index(['C'], dtype='object'))で止まってしまいます。

このエラーを回避するためにはjoinメソッドのlsuffix引数、rsuffix引数に重複する列名に追加する接尾辞を指定する必要があります。
mergeメソッドでは重複する列名には_x, _yという接尾辞がデフォルトで追加されているので、mergeメソッドで結合したDataFrameの列名はC_xとC_yになっています。この接尾辞はmergeメソッドのsuffixes引数で指定できます。
それに対して、concat関数では列名が重複していても、そのまま新しいDataFrameに追加されます。








コメント