NGSで解析したゲノムデータのアラインメントに必要なリファレンスゲノム配列としては「GRCh38/hg38」が広く用いられていますが、最近日本人について解析した「日本人基準ゲノム配列(JG2)」が公開されました。ここでは、このリファレンスゲノム配列について紹介していきます。
“リファレンスゲノム配列(GRCh38/hg38)と日本人基準ゲノム配列(JG2)” の続きを読むリファレンスゲノム配列(GRCh38/hg38)と日本人基準ゲノム配列(JG2)


ライフサイエンス研究にITの力を!
NGSで解析したゲノムデータのアラインメントに必要なリファレンスゲノム配列としては「GRCh38/hg38」が広く用いられていますが、最近日本人について解析した「日本人基準ゲノム配列(JG2)」が公開されました。ここでは、このリファレンスゲノム配列について紹介していきます。
“リファレンスゲノム配列(GRCh38/hg38)と日本人基準ゲノム配列(JG2)” の続きを読む
1000人ゲノムプロジェクト(1000 Genomes Project)は、異なる民族のヒトのゲノムサンプルを少なくとも1000人分以上解析し、遺伝的多様性のカタログを公開することを目指したプロジェクトで、2008年に開始されました。このプロジェクトはIGSRによって管理されている国際プロジェクトで、日本も含めた世界の26の集団からの3202人のゲノムデータが解析されています。
ここでは1000人ゲノムプロジェクトについてと、そのデータの利用方法について説明していきます。
“1000人ゲノムプロジェクトからデータを取得する” の続きを読む
NGSから配列データがFASTQ形式で得られたら、まずはそのクォリティをチェックする必要があります。FastQCというアプリケーションで品質チェック・管理を行うことが一般的ですが、ここではPythonのプログラムでFastQCの品質チェックを再現してみましょう。実際に手を動かして試してみれば、FastQCの品質チェックがよく理解できて、FASTQ形式のデータの理解も深まると思います。

実験の測定データにはばらつきが生じてしまいますが、測定ミスや何らかの外部的な要因でどう考えてもおかしい値が出ることがあります。しかし、そのようなデータを明確な基準もなく除外してしまっては、恣意的なデータとなってしまい、データの信頼性を落とす結果となってしまいます。もちろん、断りなくデータを除外してしまってはデータの改ざんになってしまいます。
そのようなときに、外れ値を統計的に判定する方法を持っていれば、1つの基準として使えますよね。ここでは、外れ値を統計学的に判定する方法を説明していきます。

Contents
測定データを箱ひげ図でプロットしたときの箱の大きさが四分位範囲(IQR)になり、「第3四分位点(75パーセンタイル) – 第1四分位点(25パーセンタイル)」で定義されています。
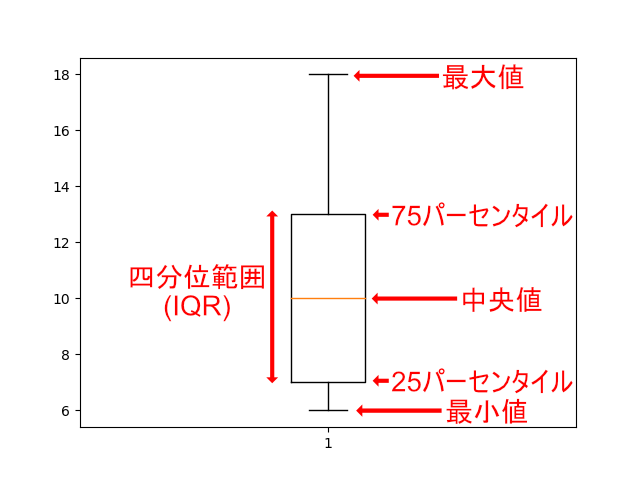
箱ひげ図については以下の記事もご覧ください。
この四分位範囲を用いて、簡易的に以下の範囲を外れ値として判定することができます。
ここで示すように、IQRから±IQR x 1.5の範囲の外を外れ値とすることが多いですが、この外れ値の範囲は任意の値で設定することができます。ただし、恣意的な値にならないように注意が必要です。
Smirnov-Grubbs検定(スミルノフ・グラブス検定)とは、データが正規分布に従うときに、測定されたデータの外れ値を検出する方法です。
まず、次のような帰無仮説と対立仮説を立てます。
測定されたデータのうち、平均値から最も外れているデータ(最大値もしくは最小値)が、他の測定データと同じ正規分布に従っているかを検定し、帰無仮説が棄却された場合にそのデータを外れ値とします。次にそのデータを除外した上で、もう一度平均値から最も外れているデータ(最大値もしくは最小値)が、他の測定データと同じ正規分布に従っているかを検定します。この操作を外れ値が出なくなるまで繰り返すのがSmirnov-Grubbs検定です。
測定されたデータの標本平均を\( \bar x\)、不偏分散を\(U\)とすると、測定データ\( x_i \)に対して標準化した統計量\(T_i\)は
$$T_i=\frac{ \vert x_i – \bar{x} \vert}{\sqrt{U}}$$
となります。
ここで、Smirnov-Grubbs検定の対立仮説は検定するデータによって「最大のものは外れ値である」もしくは「最小のものは外れ値である」になりますが、この場合は検定している時点でそのデータが正規分布のどちら側に外れているかは明らかであるので、片側検定を行います。
統計量\(T_i\)の値がSmirnov-Grubbs検定の有意点の値よりも大きければ帰無仮説を棄却し、検定しているデータは外れ値であると判断されます。
Smirnov-Grubbs検定はRのoutliersパッケージのgrubbs.test関数で実装されています。
また、Pythonでの実装は以下のサイトで公開されています(この実装は両側検定です)。
外れ値検出法はここに示したもの以外にも多く考案されています。しかし、いずれの場合も外れ値と判定されたからといってそれを安易に棄却するのではなく、外れ値が生じた原因を突き止めることを怠ってはいけません。
なお、外れ値検出に関しては以下のサイトの情報が有用であり、参考にさせていただきました。

確率からオッズやロジットといった様々な概念が生み出されています。それらを活用することで医療統計の分野などでおなじみのロジスティック回帰モデルも説明できます。でも、オッズやロジットとロジスティック回帰モデルの関係を理解できていますか?そもそも、ロジスティック回帰モデルの「ロジスティック」ってどういう意味ですか?
ここではそれらの疑問を解いていきましょう!


pandasのDataFrameで条件式を用いてデータの抽出を行う方法を説明します。データの抽出にはいくつかの方法がありますが、ここでは基本となるブールインデックス参照を用いた方法を解説していきます。

pandasのDataFrameで条件式を用いてデータの抽出を行う方法を説明します。データの抽出にはいくつかの方法がありますが、ここでは最もスマートに抽出できるqueryメソッドを用いた方法を解説します。

データ解析にはDataFrameやSeriesが非常に有用ですが、場合によっては最も単純なデータ形式であるリスト形式が必要になる場面もあります。DataFrameからリストとして取得したいデータをSeriesとして抽出してから、Seriesのto_listメソッドを用いることでリストに変換できます。

ある集団の平均値を求めるときに、そのすべてを調べるのは困難な場合は一部のサンプルの平均値を求めて元の集団の平均値を求めることがよく行われます。今回はそのような場合の、一部のサンプルの平均値(=標本平均)から元の集団の平均値(=母平均)の範囲を推定する方法をPythonを用いて説明します。

箱ひげ図を用いることでデータのばらつきを分かりやすく表現することが可能になります。ここでは、Pythonのmatplotlibを用いて箱ひげ図を描く方法を説明します。