pandasのDataFrameで条件式を用いてデータの抽出を行う方法を説明します。データの抽出にはいくつかの方法がありますが、ここでは最もスマートに抽出できるqueryメソッドを用いた方法を解説します。
開発環境
- pandas 1.0.3
- Python 3.7.7

サンプルデータ
サンプルデータとして以下のデータを用います。
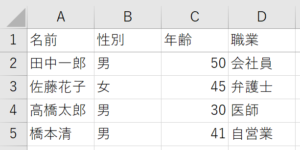
以下のようにURLを指定して、DataFrameとして取得できます。
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
DataFrameから条件式でデータを抽出する方法
DataFrameのqueryメソッドに抽出条件を文字列として指定することで、条件に合ったデータのみを抽出した新しいDataFrameを取得することができます。例えば、サンプルデータから年齢が40歳以上の人を抽出してみましょう。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
df_new = df.query('年齢 > 40')
print(df_new)
名前 性別 年齢 職業 0 田中一郎 男 50 会社員 1 佐藤花子 女 45 弁護士 3 橋本清 男 41 自営業
このようにqueryメソッドの第1引数に条件式を指定します。なお、デフォルトでは元のDataFrameには変更を加えずに条件抽出した新しいDataFrameを生成しますが、inplace引数をTrueに設定することで元のDataFrameを新しいDataFrameで置き換えます。
queryメソッドの条件式の指定方法
条件式は列ラベルを用いた比較演算子で文字列として作成します。なお、論理演算子を組み合わせて複数の条件を組み合わせることも可能です。
条件式が1つの場合
主な比較演算子
| 比較演算子 | 例 | 意味 |
|---|---|---|
| == | (列ラベル) == a | (列ラベル)の値がaに等しいもの |
| != | (列ラベル) != a | (列ラベル)の値がaと異なるもの |
| > | (列ラベル) > a | (列ラベル)の値がaより大きいもの |
| < | (列ラベル) < a | (列ラベル)の値がaより小さいもの |
| >= | (列ラベル) >= a | (列ラベル)の値がa以上のもの |
| <= | (列ラベル) <= a | (列ラベル)の値がa以下のもの |
| in | (列ラベル) in a | (列ラベル)の値がaの要素に含まれているもの (aはリストなどで指定) |
条件式の例
それでは、上記の比較演算子を用いた実際のqueryメソッドの引数の指定の仕方を見ていきましょう。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
# 年齢が40より大きい人を抽出
df1 = df.query('年齢 > 40')
# 年齢が40以上50未満の人を抽出
df2 = df.query('40 <= 年齢 < 50')
# 職業が会社員の人を抽出
df3 = df.query("職業 == '会社員'")
# 職業が弁護士か医師の人を抽出
df4 = df.query("職業 in ['弁護士', '医師']")
不等号の比較演算子は「df.query('40 <= 年齢 < 50')」のように2つを組み合わせることも可能です。また、「df3 = df.query("職業 == '会社員'")」のように条件として指定する値が文字列型の場合は、文字列をシングルクォーテーション(')で囲む必要があり、条件式自体はダブルクォーテーション(")で囲みます。
なお、列ラベルも文字列型ですがこちらはシングルクォーテーション(')等で囲ってはいけません。
複数の条件式を組み合わせる場合
主な論理演算子
| 論理演算子 | 例 | 意味 |
|---|---|---|
| or | (条件式1) or (条件式2) | (条件式1)と(条件式2)のいずれかを満たすもの(論理和) |
| and | (条件式1) and (条件式2) | (条件式1)と(条件式2)のいずれも満たすもの(論理積) |
| not | not (条件式1) | (条件式1)を満たさないもの(否定) |
条件式の例
それでは、論理演算子を用いた複数の条件式を組み合わせる方法を見ていきましょう。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
# 職業が弁護士、医師以外の人を抽出
df1 = df.query("職業 not in ['弁護士', '医師']")
# 40歳以上の男性を抽出
df2 = df.query("年齢 >= 40 and 性別 == '男'")
# 年齢以上の女性、もしくは40歳未満の人を抽出
df3 = df.query("年齢 >= 40 and 性別 == '女' or 年齢 < 40")
「df1 = df.query("職業 not in ['弁護士', '医師']")」のようにin比較演算子にnot論理演算子を組み合わせることで、inで指定した要素以外のものを抽出することができます。また、「df3 = df.query("年齢 >= 40 and 性別 == '女' or 年齢 < 40")」のように論理演算子が複数ある場合はその優先順位は以下の順番になります。
- not (条件式1)
- (条件式1) and (条件式2)
- (条件式1) or (条件式2)
これに従うと、「年齢 >= 40 and 性別 == '女' or 年齢 < 40」は「年齢 >= 40 and 性別 == '女'」or「年齢 < 40」ということになります。
条件式に変数が含まれる場合
条件式に変数が含まれる場合は以下のように変数の前に「@」をつけて区別します。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/03/dataframe-sample-01.xlsx')
yo = 40
df1 = df.query('年齢 <= @yo')
print(df1)
年齢を表す数値を変数yoに格納し、その数値以下の年齢の人を抽出しています。これを用いてDataFrameの抽出条件をプログラムの中で動的に変化させることができます。








コメント