散布図は各データの項目の値を縦軸と横軸の2つに対応させてドットをプロットしていくことで、縦軸・横軸の2次元情報の相関関係やデータの分布を可視化するための図です。また、縦軸・横軸だけでなく、ドットの色もデータの値によって変化させることで3つの項目の関係(3次元情報)を可視化することもできます。ここでは、Pythonのmatplotlibを用いて散布図を描く方法を説明します。
開発環境
- matplotlib 3.1.3
- Pandas 1.0.3
- Python 3.7.7

基本的な散布図の描画方法
Axesクラスのscatterメソッドを用いて散布図を描画できます。
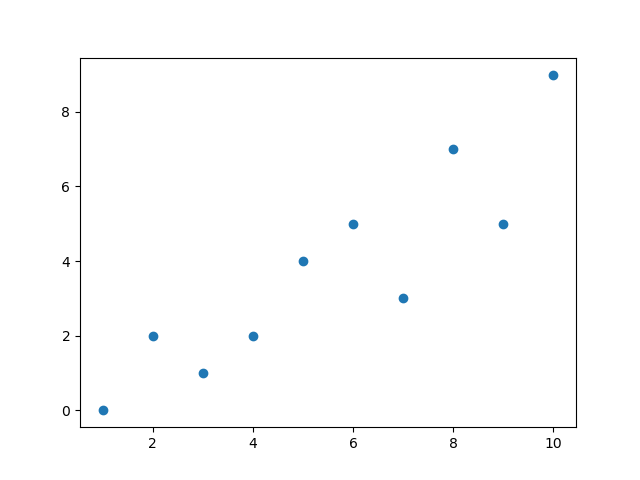
基本的な使い方①:デフォルト設定での描画
まずは基本として、最もシンプルな描画方法を見ていきましょう。
scatterメソッドのx引数、y引数にそれぞれデータの横軸(X座標)・縦軸(Y座標)の値のリストやSeriesを指定することで、散布図を作成できます。
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [0, 2, 1, 2, 4, 5, 3, 7, 5, 9]
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.scatter(x, y)
plt.show()
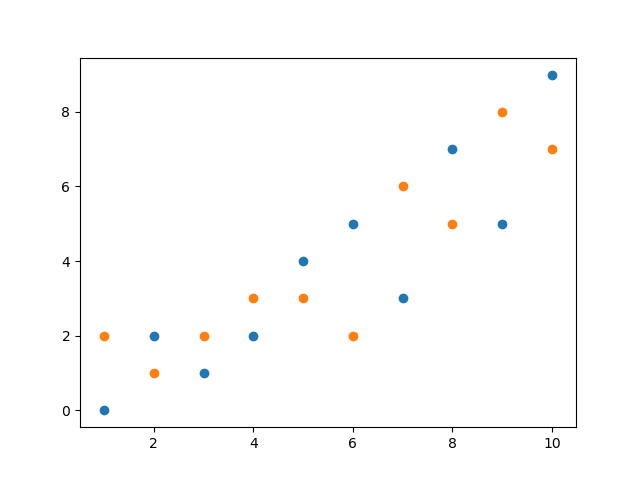
基本的な使い方②:複数のデータを1つの散布図に表示する方法
複数のデータを散布図で描画する場合は、Axesオブジェクトにscatterメソッドで散布図を追加していくだけで自動的に色分けした散布図を作成してくれます。
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y1 = [0, 2, 1, 2, 4, 5, 3, 7, 5, 9]
y2 = [2, 1, 2, 3, 3, 2, 6, 5, 8, 7]
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.scatter(x, y1)
ax.scatter(x, y2)
plt.show()
基本的な使い方③:data引数にDataFrameを指定する方法
scatterメソッドのdata引数にDataFrameを指定することもできます。この場合はx引数、y引数には、data引数に指定したDataFrameの中でのどの系列を散布図として描画するのかを指定する必要があります。(DataFrameの列ラベルでデータ系列を指定します)
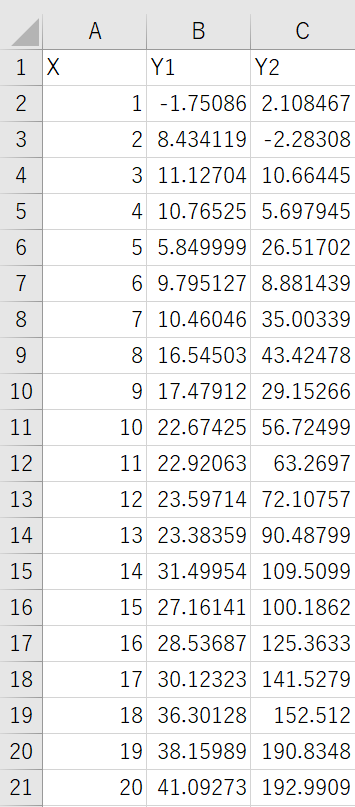
例えばサンプルデータとして次のエクセルデータを使用します。このデータは以下からダウンロード可能です。
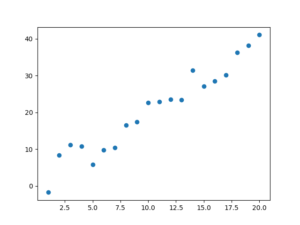
このエクセルデータにはX、Y1、Y2の3つの系列があり、X系列を横軸に、Y1系列を縦軸にしてグラフ化してみます。scatterメソッドのx引数、y引数にそれぞれ’X’、’Y1’を指定しましょう。
import pandas as pd
df = pd.read_excel('https://biotech-lab.org/wp-content/uploads/2020/08/4907-Sample-01.xlsx')
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.scatter('X', 'Y1', data = df)
plt.show()
散布図のスタイルの設定
scatterメソッドの引数に指定することで、散布図のスタイルを変えることができます。
マーカーのスタイル(種類・サイズ・色など)を変える
マーカーの種類を指定する
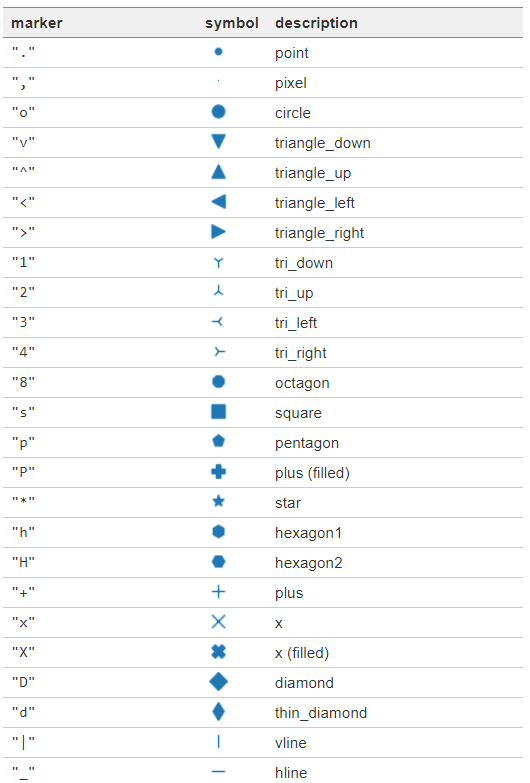
マーカーの種類はmarker引数で指定します。marker引数にはこちらで定義されたマーカー名を指定することができます。主に用いられる代表的なマーカーは次に示す通りです。
なお、マーカー名で文字列で’1’と指定するのと、数字で1と指定するのでは別のマーカーを表しますのでご注意ください。
マーカーのサイズを指定する
マーカーのサイズはs引数で指定します。なお、マーカーサイズは\((ポイント数)^2\)で指定するので注意が必要です。
マーカーの色を指定する
マーカーの色はc引数で指定します。色の指定方法はこちらをご覧ください。
その他のスタイルの設定
輪郭の太さ(linewidths引数)、輪郭の色(edgecolors引数)、透明度(alpha引数)などが設定可能です。
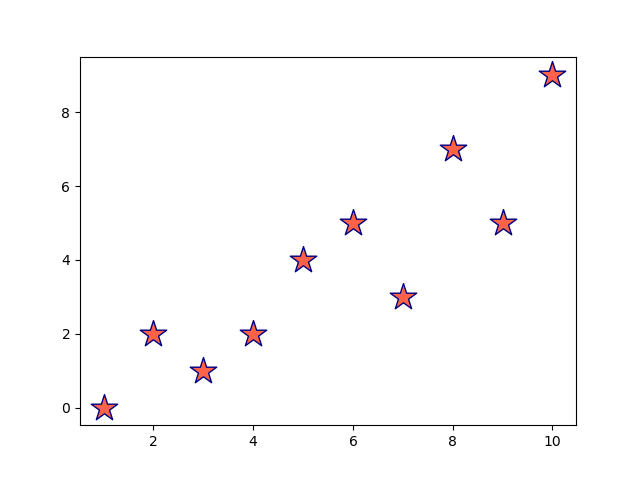
最後にサンプルコードをお示しします。
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
y = [0, 2, 1, 2, 4, 5, 3, 7, 5, 9]
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.scatter(x, y, s=400, c='tomato', marker='*', linewidths=1, edgecolors='navy')
plt.show()
マーカーの色をカラーマップで指定する
データの値によってマーカーの色を変えて散布図に表示させることができます。これによって、データを横軸・縦軸に加えて色の情報の3次元で可視化することが可能になります。ここでは例として機械学習などでよく用いられるボストン住宅価格に関するデータセットを用いてみましょう。データセットの詳細は以下の記事をご覧ください。

scatterメソッドのx引数、y引数に加えて、マーカーの色を指定するc引数にデータ系列を指定することで、マーカーの色をデータの値によって変えることができます。マーカーの色とデータの値の対応はcmap引数にカラーマップを指定することで行います(使用可能なカラーマップはmatplotlib.cmモジュールに格納されています)。
from sklearn import datasets
import pandas as pd
# データセットをDataFrameとして読み込みます
boston = datasets.load_boston()
boston_df = pd.DataFrame(boston['data'], columns=boston['feature_names'])
boston_df['MEDV'] = boston['target']
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
# 散布図を作成し、PathCollectionインスタンスとして取得する
mappable = ax.scatter(boston_df['DIS'], boston_df['LSTAT'], c=boston_df['MEDV'] ,cmap='coolwarm')
# 作成した散布図から、そのカラーバーをfigに追加する
fig.colorbar(mappable)
ax.set_xlabel('雇用施設からの距離', fontname="MS Gothic")
ax.set_ylabel('低所得者の割合', fontname="MS Gothic")
plt.show()
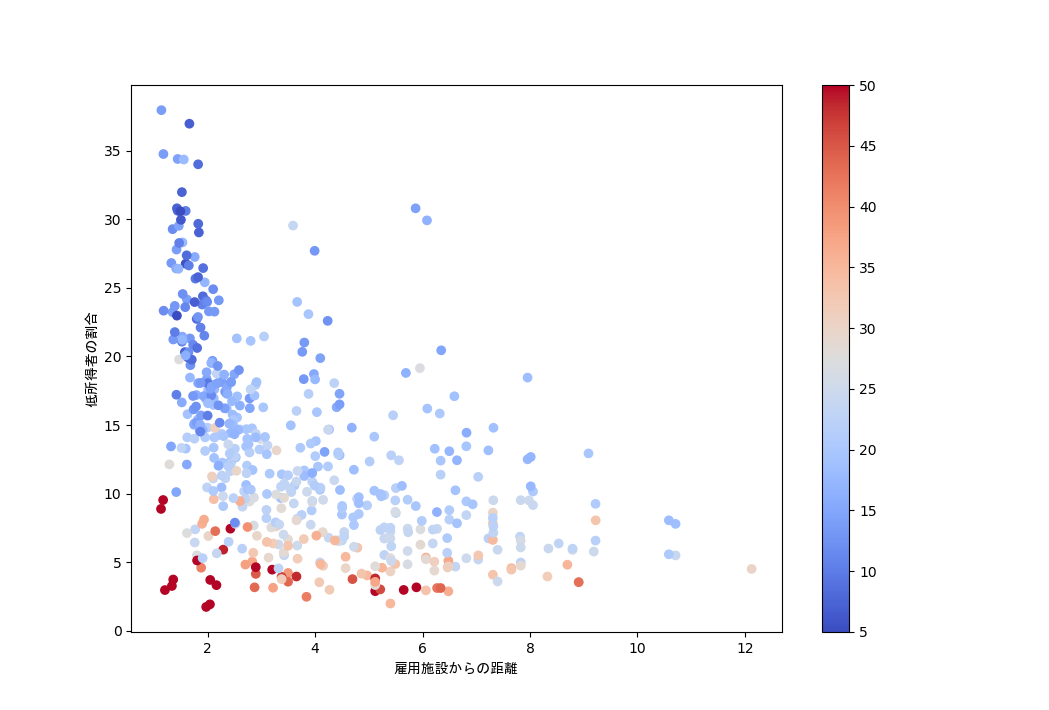
ここでは、横軸が「ボストン市の5つの雇用施設からの距離」、縦軸が「低所得者の割合」となっていて、散布図の点の色が住宅価格(赤が高くて、青が安い)です。これを見ると、低所得者の割合が低い地区の方が住宅価格が高く、雇用施設から離れるほど住宅価格は低くなることが分かります。また、雇用施設から遠い場所には低所得者が多くないことも分かります(移動手段の問題?)。
このように、マーカーの色をカラーマップで指定することで、3つの次元のデータを可視化することもできます。








コメント