PandasのDataFrameの1つ1つの列や行は、Seriesと呼ばれる1次元配列にインデックス(ラベル)を付けたオブジェクトで構成されています。Seriesは同じ一次元配列であるリストや、ラベル付きの配列である辞書よりも高度な操作が操作が可能であり、またSeriesの要素ごとの四則演算も行うことができます。ここではSeriesオブジェクトの作成方法とその活用法を説明します。
Seriesの作成
PandasにおけるSeriesはnumpy.ndarrayの1次元配列にインデックス(ラベル)を付けたものに相当し、複数のSeriesを組み合わせることでDataFrameになります。DataFrameから列や行を抽出することでもSeriesを取得することができますが、新規にSeriesを作成する場合は次のようにします。
リストからSeriesを作成する
Seriesクラスのコンストラクタ(__init__)にリストを指定するだけで、そのリストをSeriesに変換することができます。例えば、「10, 20, 30, 40, 50」を要素とするSeriesを作成してみましょう。
import pandas as pd
a = pd.Series([10, 20, 30, 40, 50])
print(a)
0 10 1 20 2 30 3 40 4 50 dtype: int64
インデックスに何も指定しない場合はデフォルトで「0, 1, 2, 3, …」が割り当てられます。インデックスを指定する場合は次のように、index引数にリストで指定できます。
import pandas as pd
a = pd.Series([10, 20, 30, 40, 50], index=['a', 'b', 'c', 'd', 'e'])
print(a)
a 10 b 20 c 30 d 40 e 50 dtype: int64
辞書からSeriesを作成する
Seriesクラスのコンストラクタ(__init__)に辞書を指定することで、インデックスと値を同時に指定することができます。
import pandas as pd
a = pd.Series({'a':10, 'b':20, 'c':30, 'd':40, 'e':50})
print(a)
a 10 b 20 c 30 d 40 e 50 dtype: int64
Seriesの特徴とその活用
データ処理や統計解析に関するメソッドが用意されている
Seriesクラスにはデータ処理や統計解析に関する様々なメソッドが用意されていて、リストや辞書・ndarrayからSeriesオブジェクトへと変換することでそれらのメソッドが使用可能となります。Seriesクラスで使用可能な機能は以下のAPIドキュメントをご覧ください。
Series同士の四則演算
Seriesはndarrayと同様に、Series同士の四則演算は要素ごとの四則演算となり、またブロードキャストにも対応しているのも大きな特徴です。
例えばリストでは四則演算を行うと次のようになり、リスト同士の足し算はそのリストの要素を単純に後ろに付け加える処理になります。
a = [1, 2, 3, 4, 5]
b = [1, 2, 3, 4, 5]
print(a + b)
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
同様の処理をSeriesで行うとどうなるでしょうか?
import pandas as pd
a = pd.Series([1, 2, 3, 4, 5])
b = pd.Series([1, 2, 3, 4, 5])
print(a + b)
0 2 1 4 2 6 3 8 4 10 dtype: int64
Seriesの要素ごとに足し算が行われていることが分かります。なお、この演算は Seriesに登録されたデータの順番ではなく、 対応するインデックスの要素ごとに処理が行われます。
import pandas as pd
a = pd.Series([1, 2, 3, 4, 5], index=['A', 'B', 'C', 'D', 'E'])
b = pd.Series([1, 2, 3, 4, 5], index=['E', 'D', 'C', 'B', 'A'])
print(a + b)
A 6 B 6 C 6 D 6 E 6 dtype: int64
そのためSeriesに登録されたデータの順番とインデックスの順番がずれている場合は、上記のようになります。なお、対応するインデックスのものがない場合はNaNが代入されます。
活用例:データの可視化
Seriesでの四則演算が要素ごとの四則演算になることは、例えばデータをグラフで表す際に非常に便利です。以下の2つのデータ系列があって
- y1:[1, 5, 9, 15, 13, 17]
- y2:[9, 11, 13, 14, 17, 15]
y1とy2の値を積み上げて、以下のように下の部分の面積がy1を、上の部分の面積がy2を表すようなグラフを考えてみましょう。
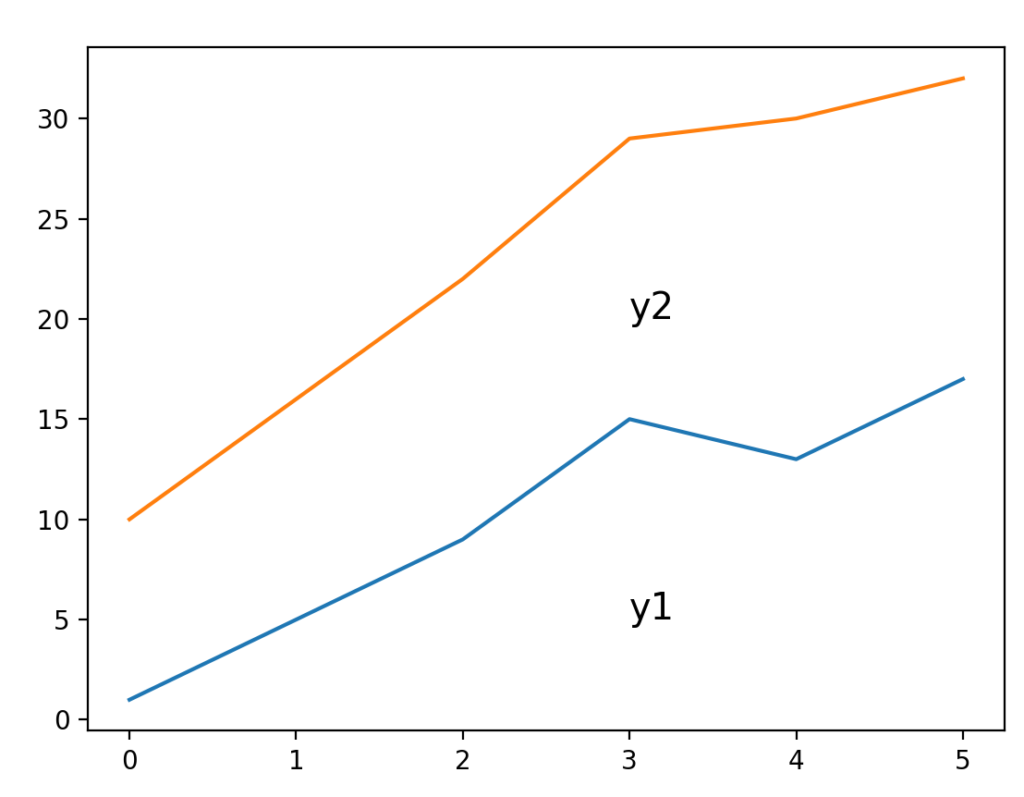
この時オレンジの折れ線グラフの値はy1とy2を足したものになりますが、Seriesであれば以下のように単純に足し算するだけでOKです。
import pandas as pd
import matplotlib.pyplot as plt
y1 = pd.Series([1, 5, 9, 15, 13, 17])
y2 = pd.Series([9, 11, 13, 14, 17, 15])
fig, ax = plt.subplots()
ax.plot(y1)
ax.plot(y1 + y2)
ax.text(3, 5, 'y1', fontsize='x-large')
ax.text(3, 20, 'y2', fontsize='x-large')
plt.show()
同様のことはndarrayでも実現できますが、Seriesではデータ自体にインデックス(ラベル)をつけれるという利点があります。








コメント