各地のCOVID-19の感染者動向に関するオープンデータは東京都のGitHubリポジトリからフォークして提供されています。各地のデータは類似したフォーマットで提供されているので、そのデータを可視化してみましょう。ここでは、大阪府のデータを例にして説明していきます。
※ この記事の方法では最新のデータは取得できない可能性があります。
開発環境
- matplotlib 3.1.3
- Pandas 1.0.3
- Python 3.7.7

オープンデータを取得する
COVID-19の感染者動向に関するオープンデータについてはこちらでまとめています。


東京都のGitHubリポジトリからフォークして作成されており、感染者情報の大元となるデータの data.json の構成は基本的に共通となっております。
この記事では、このdata.jsonを解析していきましょう。代表的な自治体のデータ data.json は以下のURLから取得できます。なお、自治体によっては data.json が公開されていなかったり、構成が異なったりしていますのでご注意ください。
- 東京都 : https://raw.githubusercontent.com/tokyo-metropolitan-gov/covid19/development/data/data.json
- 大阪府 : https://raw.githubusercontent.com/codeforosaka/covid19/development/data/data.json
- 京都府 : https://raw.githubusercontent.com/stopcovid19-kyoto/covid19/development/data/data.json
このデータには次に示す通り、「感染者を示す番号、日付、居住地、年代、性別、退院・解除」の情報が含まれており、感染者についての最小限の情報を表しています。各自治体で、このdata.jsonに加えて独自の情報を付加したデータベースファイルを公開しているようです。
データベースの運用の仕方は各自治体によってさまざまで、例えば東京都では居住地の欄は「都内 or 都外」で大雑把に分けているのに対して、大阪府では居住地に市町村名が登録されています。
以下では、この大阪府のデータを例に説明していきます。

居住地別の感染者数を表にまとめる
まずは、先ほどのデータベースから各市町村の累積感染者数と現在入院・療養中の感染者数を求めてみます。
import pandas as pd
import requests
# データを取得する
URL='https://raw.githubusercontent.com/codeforosaka/covid19/development/data/data.json'
r=requests.get(URL)
df = pd.json_normalize(r.json(), ['patients', 'data'])
# 居住地別の累積感染者数をSeriesで取得する
count_city = df.groupby('居住地').count().iloc[:,0]
# 居住地別の入院・療養中感染者数をSeriesで取得する
df = df.set_index(['退院'])
count_city_active = df.loc[''].groupby('居住地').count().iloc[:,0]
# 取得したデータをDataFrameにまとめる
df_result = pd.DataFrame({'累積感染者数':count_city, '入院・療養中感染者数':count_city_active})
print(df_result)
累積感染者数 入院・療養中感染者数 交野市 22 4.0 八尾市 190 41.0 千早赤阪村 1 1.0 吹田市 245 33.0 和泉市 90 24.0 ...(略)... 貝塚市 24 6.0 門真市 76 19.0 阪南市 10 1.0 高槻市 98 25.0 高石市 31 8.0
これで上記のように求めることができました。
なお、ここで取得した入院・療養中感染者数の人数が大阪府の発表と若干の違いがあったので、あくまでも参考地としてご確認ください。例えば「入院待機中の人は入院・療養中に含まれない」など、データの扱い方がこちらの想定と微妙にずれている可能性があります。
居住地別の感染者数を可視化する
続いて、各市町村ごとの感染者数を棒グラフで表して、年齢別に層別化して傾向を見てみましょう。
import pandas as pd
import requests
# データを取得
URL='https://raw.githubusercontent.com/codeforosaka/covid19/development/data/data.json'
r=requests.get(URL)
df = pd.json_normalize(r.json(), ['patients', 'data'])
# インデックスを設定
df = df.set_index(['年代'])
# 層別化されたそれぞれの要素を格納する辞書
count_dict = {}
# 層別化する年齢のリスト
ages = ['未就学児', '就学児', '10代', '20代', '30代', '40代', '50代', '60代', '70代', '80代', '90代', '100代']
# 年代ごとに抽出して、層別化する
for age in ages:
df_tmp = df.loc[age]
count_dict[age] = df_tmp.groupby('居住地').count().iloc[:,0]
# 年齢で層別化された各市町村ごとの感染者数を表すDataFrame(グラフ化のために縦横を入れ替え)
df_categorized = pd.DataFrame(count_dict).T
# 積み上げ棒グラフに描画する
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.xticks(fontname="MS Gothic", rotation=90)
for i in range(len(df_categorized)):
ax.bar(df_categorized.columns, df_categorized.iloc[i], bottom = df_categorized.iloc[:i].sum())
ax.legend(df_categorized.index, prop={"family":"MS Gothic"})
plt.show()
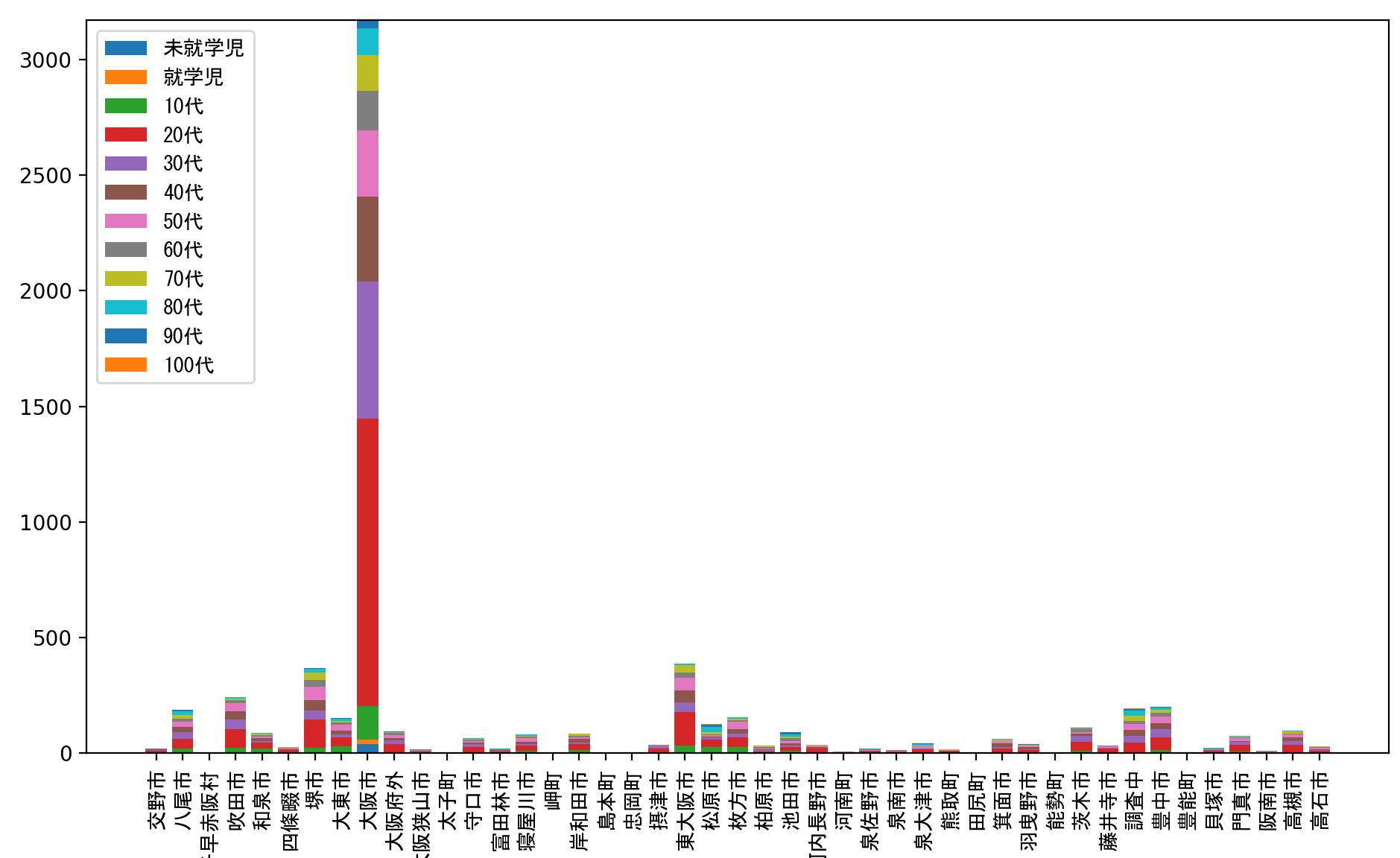
これで市町村別の年齢で層別化された感染者数がグラフ化されましたが、如何せん大阪市が多すぎてほかの市町村のデータが見にくくなってしまっています。
次に、先ほどのプログラムの24行目を次のように差し替えて、大阪市のデータだけ除外してみましょう。
df_categorized = pd.DataFrame(count_dict).drop('大阪市').T
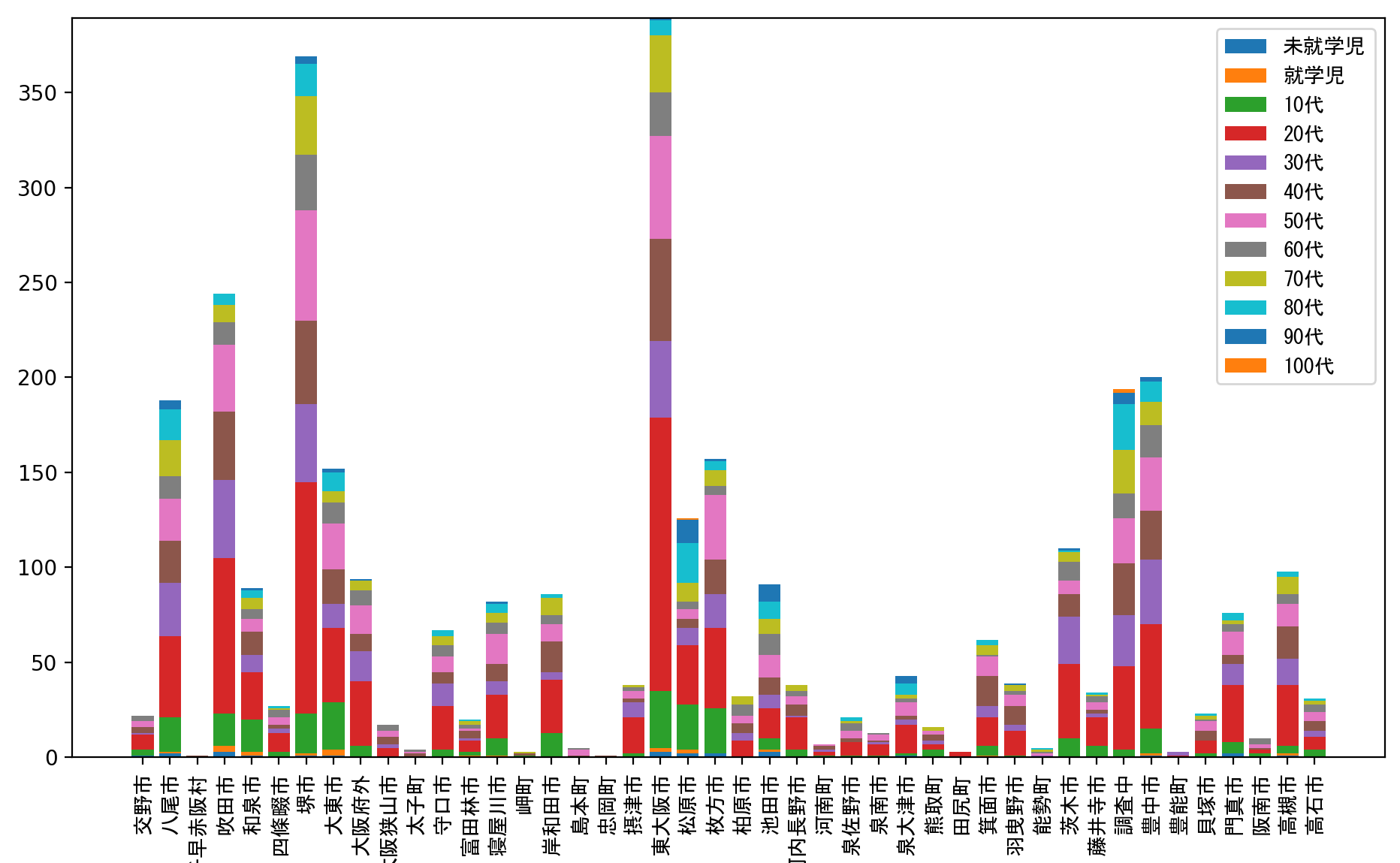
ちなみに、大阪府のデータには年齢を表す表現で「20代」と「20」というのが混在しているのですが、「20」という表記は初期のごく一部のみなので、ここでは簡単のために除外しています。
居住地別のアクティブな感染者数を可視化する
次に、現在入院中・療養中の感染者について、先ほどと同様に居住地別の年齢で層別化して棒グラフで表してみましょう。
import pandas as pd
import requests
# データを取得
URL='https://raw.githubusercontent.com/codeforosaka/covid19/development/data/data.json'
r=requests.get(URL)
df = pd.json_normalize(r.json(), ['patients', 'data'])
# マルチインデックスを設定
df = df.set_index(['退院', '年代'])
# 入院・療養中感染者数のみを抽出する
df = df.loc['']
# 層別化されたそれぞれの要素を格納する辞書
count_dict = {}
# 層別化する年齢のリスト
ages = ['未就学児', '就学児', '10代', '20代', '30代', '40代', '50代', '60代', '70代', '80代', '90代']
# 年代ごとに抽出して、層別化する
for age in ages:
df_tmp = df.loc[age]
count_dict[age] = df_tmp.groupby('居住地').count().iloc[:,0]
# 年齢で層別化された各市町村ごとの感染者数を表すDataFrame(グラフ化のために縦横を入れ替え)
df_categorized = pd.DataFrame(count_dict).T
# 積み上げ棒グラフに描画する
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.xticks(fontname="MS Gothic", rotation=90)
for i in range(len(df_categorized)):
ax.bar(df_categorized.columns, df_categorized.iloc[i], bottom = df_categorized.iloc[:i].sum())
ax.legend(df_categorized.index, prop={"family":"MS Gothic"})
plt.show()

やはりこの結果も大阪市が突出しすぎていてほかの自治体が見にくいので、大阪市を除外したグラフも作っておきます。先ほどと同様にプログラムの26行目を次と差し替えます。
df_categorized = pd.DataFrame(count_dict).drop('大阪市').T
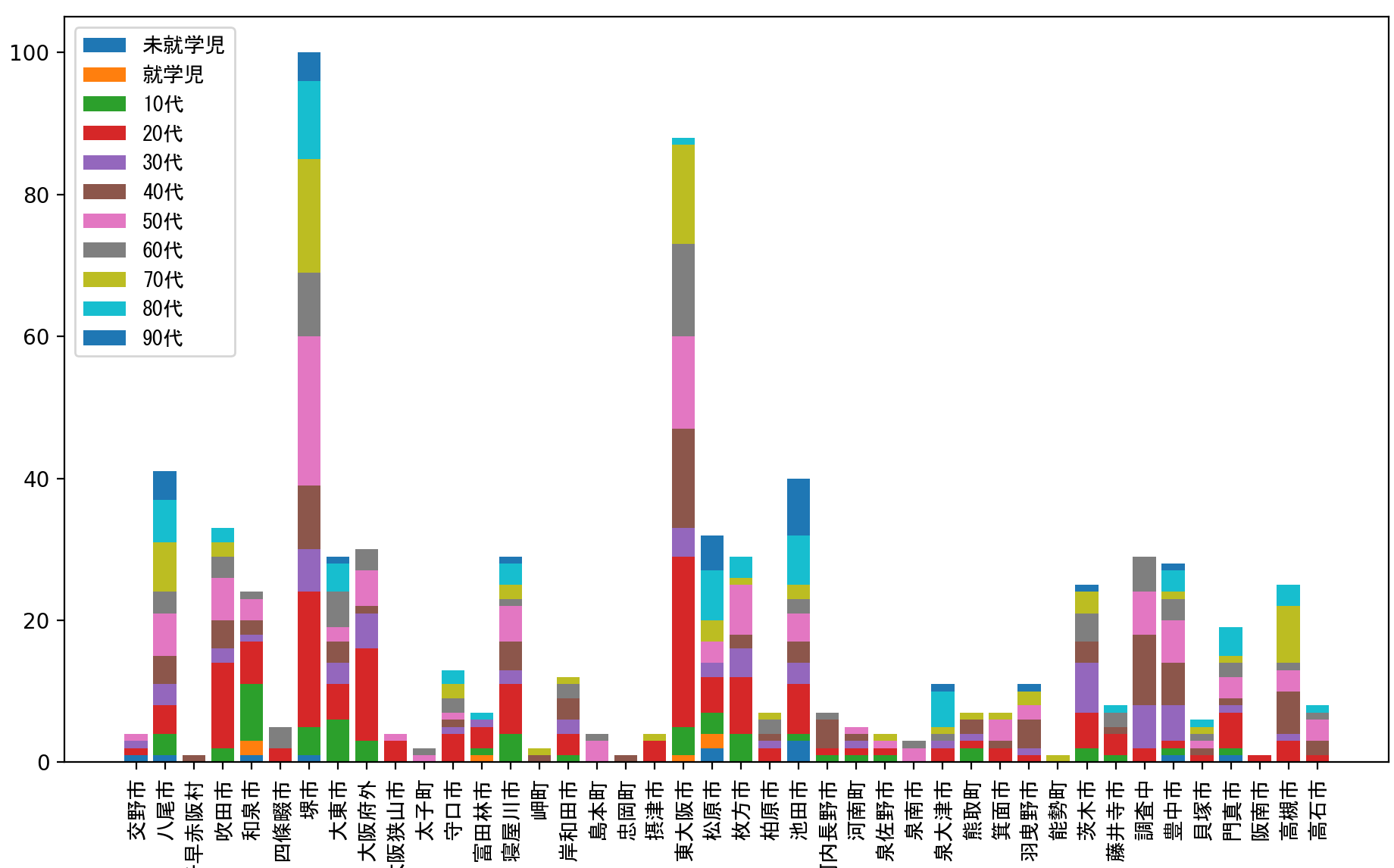
新規感染者数の推移を年齢で層別化する
最後に、新規感染者数を年齢で層別化してグラフ化します。
import pandas as pd
import requests
# データを取得
URL='https://raw.githubusercontent.com/codeforosaka/covid19/development/data/data.json'
r=requests.get(URL)
df = pd.json_normalize(r.json(), ['patients', 'data'])
# インデックスを設定
df = df.set_index(['date'])
# 層別化されたそれぞれの要素を格納する辞書
categorized_dict = {}
# # 日付ごとに抽出して、年齢で層別化する
for date in df.index:
# その日の人数が一人の場合は、Seriesの形状を整える
if type(df.loc[date]) is pd.Series:
series_tmp = pd.Series({df.loc[date].loc['年代'] : 1})
else:
series_tmp = df.loc[date].groupby('年代').count().iloc[:,0]
# 年齢が「20」と「20代」の2通りあるので、「20代」の形式にそろえる
new_index_list = []
flag = False
for i in range(len(series_tmp.index)):
if series_tmp.index[i].isdecimal():
flag = True
new_index_list.append(series_tmp.index[i] + '代')
elif series_tmp.index[i] == '未就学児':
new_index_list.append('未就学児')
elif series_tmp.index[i] == '就学児':
new_index_list.append('就学児')
if flag:
series_tmp.index = new_index_list
categorized_dict[date] = series_tmp
# DataFrameに変換する
df_categorized = pd.DataFrame(categorized_dict)
# 積み上げ棒グラフに描画する
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.xticks(fontname="MS Gothic", rotation=90)
for i in range(len(df_categorized)):
ax.bar(df_categorized.columns, df_categorized.iloc[i], bottom = df_categorized.iloc[:i].sum())
ax.legend(df_categorized.index, prop={"family":"MS Gothic"}, loc='upper left')
plt.show()

いかがでしょうか?ここでは、日ごとの感染者数をグラフ化しましたが、年齢別の感染者数の傾向を見るのであれば1週間ごとに集計したデータをグラフ化した方がいいのかもしれませんね。
若干の修正が必要な場合もありますが、URLをほかの自治体のデータに差し替えてグラフ化することもできますので、ぜひチャレンジしてみてくださいね!








コメント