データをモデル化する際に、「男性 / 女性」のようなカテゴリ変数はそのままではモデルに組み込むことができません。モデル化するには何らかの方法で数値化する必要があります。
ここではデータ解析の前処理としてカテゴリ変数を数値化する方法を説明していきます。
開発環境
- pandas 1.2.4
- Python 3.8.8
- scikit-learn 0.24.1

カテゴリ変数の数値化手法
カテゴリ変数とは名義変数や尺度変数による離散量のデータのことで、その値が集合{A, B, C, D, … }の中の任意の1つの値であるような変数のことを言います。例えば代表的なカテゴリ変数である性別は{男性, 女性}のいずれかの値(カテゴリ)を持つ変数といえます。しかし、機械学習のモデルを作成するときには変数を数式に組み込む必要があるので、例えば「男性 / 女性」のような値をそのままモデルに組み込むことはできません。そこで「男性 → 0、女性 → 1」のように数値に変換する必要が出てきます。
ここでは、カテゴリ変数をモデル化に使える数値変数に変換する方法を説明していきます。なお、サンプルのデータセットとしてseabornのサンプルデータに含まれるタイタニック号の沈没事故の生存/死亡者のデータを用います。
import seaborn as sns
titanic_data = sns.load_dataset('titanic')
print(titanic_data)
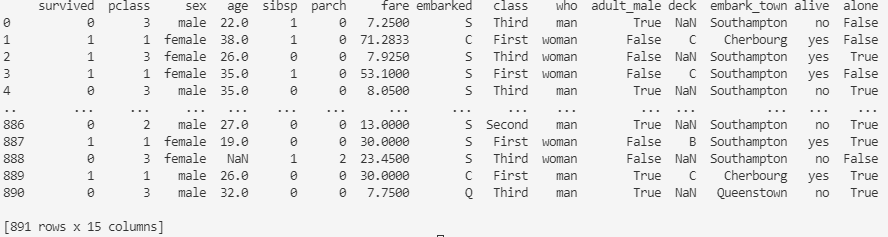
このデータセットには多くのデータが含まれているので、ここでは特に、「survived / class / sex / age / embark_town」に絞ってみていきましょう。なお、欠損値はあらかじめ除外しておきます。
titanic_data = titanic_data[['survived', 'class', 'sex', 'age', 'embark_town']]
titanic_data = titanic_data.dropna()
print(titanic_data)
survived class sex age embark_town 0 0 Third male 22.0 Southampton 1 1 First female 38.0 Cherbourg 2 1 Third female 26.0 Southampton 3 1 First female 35.0 Southampton 4 0 Third male 35.0 Southampton .. ... ... ... ... ... 885 0 Third female 39.0 Queenstown 886 0 Second male 27.0 Southampton 887 1 First female 19.0 Southampton 889 1 First male 26.0 Cherbourg 890 0 Third male 32.0 Queenstown [712 rows x 5 columns]
上記のうちclass(船室階級)、sex(性別)、embark_town(出港地)がカテゴリ変数に該当します。なお、survivedについても本来はカテゴリ変数ですが、「死亡 → 0、生存 → 1」として数値化された状態です。
「生存 / 死亡」「男性 / 女性」のような2値のみのカテゴリ変数はどのような手法で数値化しても同じ結果になるのですが、3値以上のカテゴリ変数については「その順番に意味があるのか、どの程度の重みづけが必要なのか」によって様々な数値化の手法があります。ここでは代表的な数値化手法について説明していきます。
均等にカテゴリを数値化する:Label Encoding
まず最初に考えられる方法は、それぞれのカテゴリを順番に並べて「0, 1, 2, 3, …」と番号を振っていく方法です。このように順番にカテゴリを数値化する方法をLabel Encodingと呼びます。
カテゴリの順序を自動で決める方法
scikit-learnのLabelEncoderを用いて、それぞれのカテゴリに自動で数値を割り当てることができます。なお、この時の数値はABC順で自動的に決められ、以下のように割り当てられます。
- class(船室階級):「First → 0、Second → 1、Third → 2」
- sex(性別):「female → 0、male → 1」
- embark_town(出港地):「Cherbourg → 0、Queenstown → 1、Southampton → 2」
from sklearn.preprocessing import LabelEncoder
# 船室階級の数値化
class_le = LabelEncoder()
titanic_data['class'] = class_le.fit_transform(titanic_data['class'])
# 性別の数値化
sex_le = LabelEncoder()
titanic_data['sex'] = sex_le.fit_transform(titanic_data['sex'])
# 出港地の数値化
town_le = LabelEncoder()
titanic_data['embark_town'] = town_le.fit_transform(titanic_data['embark_town'])
print(titanic_data)
survived class sex age embark_town 0 0 2 1 22.0 2 1 1 0 0 38.0 0 2 1 2 0 26.0 2 3 1 0 0 35.0 2 4 0 2 1 35.0 2 .. ... ... ... ... ... 885 0 2 0 39.0 1 886 0 1 1 27.0 2 887 1 0 0 19.0 2 889 1 0 1 26.0 0 890 0 2 1 32.0 1 [712 rows x 5 columns]
数値化されたカテゴリーの一覧はLabelEncoderインスタンスのclasses_属性に格納されています。例えば出港地については
print(town_le.classes_)
['Cherbourg' 'Queenstown' 'Southampton']
となり、左から順番に0, 1, 2となっていることが分かります。
カテゴリの順序を自分で指定する方法
モデルによってはカテゴリの順番も重要な要素になってくるので、そのような場合は自分で順番を指定する必要があります。ここでは先ほどとは反対に以下のように数値を割り当てます。
- class(船室階級):「First → 2、Second → 1、Third → 0」
- sex(性別):「female → 1、male → 0」
- embark_town(出港地):「Cherbourg → 2、Queenstown → 1、Southampton → 0」
LabelEncoderを用いる方法
LabelEncoderで数値化するカテゴリの順番を変更したい場合は、classes_属性にカテゴリ名のリストで指定します。
from sklearn.preprocessing import LabelEncoder
# 船室階級の数値化
class_le = LabelEncoder()
class_le.classes_ = ['Third', 'Second', 'First']
titanic_data['class'] = class_le.transform(titanic_data['class'])
# 性別の数値化
sex_le = LabelEncoder()
sex_le.classes_ = ['male', 'female']
titanic_data['sex'] = sex_le.transform(titanic_data['sex'])
# 出港地の数値化
town_le = LabelEncoder()
town_le.classes_ = ['Southampton', 'Queenstown', 'Cherbourg']
titanic_data['embark_town'] = town_le.transform(titanic_data['embark_town'])
print(titanic_data)
survived class sex age embark_town 0 0 0 0 22.0 0 1 1 2 1 38.0 2 2 1 0 1 26.0 0 3 1 2 1 35.0 0 4 0 0 0 35.0 0 .. ... ... ... ... ... 885 0 0 1 39.0 1 886 0 1 0 27.0 0 887 1 2 1 19.0 0 889 1 2 0 26.0 2 890 0 0 0 32.0 1 [712 rows x 5 columns]
Series.mapメソッドを用いる方法
pandasのSeries.mapメソッドではカテゴリを対応する数値を明示的に指定することができるので、それを用いてカテゴリの順序を自分で指定することができます。
# 船室階級の数値化
class_mapping = {'First':2, 'Second':1, 'Third':0}
titanic_data['class'] = titanic_data['class'].map(class_mapping)
# 性別の数値化
sex_mapping = {'female':1, 'male':0}
titanic_data['sex'] = titanic_data['sex'].map(sex_mapping)
# 出港地の数値化
town_mapping = {'Cherbourg':2, 'Queenstown':1, 'Southampton':0}
titanic_data['embark_town'] = titanic_data['embark_town'].map(town_mapping)
print(titanic_data)
survived class sex age embark_town 0 0 0 0 22.0 0 1 1 2 1 38.0 2 2 1 0 1 26.0 0 3 1 2 1 35.0 0 4 0 0 0 35.0 0 .. ... ... ... ... ... 885 0 0 1 39.0 1 886 0 1 0 27.0 0 887 1 2 1 19.0 0 889 1 2 0 26.0 2 890 0 0 0 32.0 1 [712 rows x 5 columns]
これでそれぞれのカテゴリを指定した数値に変換することができました。
重みづけをしてカテゴリを数値化する
3つ以上のカテゴリがある場合は、回帰モデルにおいてはどのような順序で数値化するかに加えて、どのように重みづけして数値化するかは非常に重要な要素です。例えばロジスティック回帰モデルでは、説明変数\(x_1, x_2, x_3, … ,x_n\)を用いて
$$logit(p)=a_1*x_1+a_2*x_2+a_3*x_3+…+a_n*x_n+b$$
と表し、数値化したカテゴリの値を\(x_1, x_2, x_3, … ,x_n\)に代入するので、3つ以上のカテゴリの場合はその順序と重みづけが結果に直接かかわってきます。
先ほどのSeries.mapメソッドを用いてカテゴリを数値化する方法では、それぞれのカテゴリの数値を直接指定することができるので、ここではそれを用いてカテゴリに重みづけした数値を指定する方法を見ていきましょう。
Count Encoding
Count Encodingはそれぞれのカテゴリのデータの出現回数によってそのカテゴリを数値化する方法です。
# 船室階級の数値化
class_mapping = titanic_data['class'].value_counts().to_dict()
titanic_data['class'] = titanic_data['class'].map(class_mapping)
# 性別の数値化
sex_mapping = titanic_data['sex'].value_counts().to_dict()
titanic_data['sex'] = titanic_data['sex'].map(sex_mapping)
# 出港地の数値化
town_mapping = titanic_data['embark_town'].value_counts().to_dict()
titanic_data['embark_town'] = titanic_data['embark_town'].map(town_mapping)
print(titanic_data)
survived class sex age embark_town 0 0 355 453 22.0 554 1 1 184 259 38.0 130 2 1 355 259 26.0 554 3 1 184 259 35.0 554 4 0 355 453 35.0 554 .. ... ... ... ... ... 885 0 355 259 39.0 28 886 0 173 453 27.0 554 887 1 184 259 19.0 554 889 1 184 453 26.0 130 890 0 355 453 32.0 28 [712 rows x 5 columns]
ここではそれぞれのカテゴリの出現回数に応じて以下のように数値化しています。
- class(船室階級):「First → 184、Second → 173、Third → 355」
- sex(性別):「female → 259、male → 453」
- embark_town(出港地):「Cherbourg → 130、Queenstown → 28、Southampton → 554」
なお、データの出現回数によってカテゴリを並べ替えて、0, 1, 2, … という数値に置き換える方法もあり、そちらはLabel-Count Encodingと呼ばれています。
Target Encoding
Target Encodingはそのカテゴリにおける目的変数の平均値によってそのカテゴリを数値化する方法です。そのカテゴリが結果に与える影響の重みづけは、それぞれのカテゴリの目的変数の平均を考えるのが直感的にも分かりやすく、シンプルな方法です。
# 船室階級の数値化
class_mapping = titanic_data[['class', 'survived']].groupby(['class'])['survived'].mean().to_dict()
titanic_data['class'] = titanic_data['class'].map(class_mapping)
# 性別の数値化
sex_mapping = titanic_data[['sex', 'survived']].groupby(['sex'])['survived'].mean().to_dict()
titanic_data['sex'] = titanic_data['sex'].map(sex_mapping)
# 出港地の数値化
town_mapping = titanic_data[['embark_town', 'survived']].groupby(['embark_town'])['survived'].mean().to_dict()
titanic_data['embark_town'] = titanic_data['embark_town'].map(town_mapping)
print(titanic_data)
survived class sex age embark_town 0 0 0.239437 0.205298 22.0 0.362816 1 1 0.652174 0.752896 38.0 0.607692 2 1 0.239437 0.752896 26.0 0.362816 3 1 0.652174 0.752896 35.0 0.362816 4 0 0.239437 0.205298 35.0 0.362816 .. ... ... ... ... ... 885 0 0.239437 0.752896 39.0 0.285714 886 0 0.479769 0.205298 27.0 0.362816 887 1 0.652174 0.752896 19.0 0.362816 889 1 0.652174 0.205298 26.0 0.607692 890 0 0.239437 0.205298 32.0 0.285714 [712 rows x 5 columns]
ここではそれぞれのカテゴリのsurvivedの平均値に応じて以下のように数値化しています。
- class(船室階級):「First → 0.6521…、Second → 0.4797…、Third → 0.2394…」
- sex(性別):「female → 0.7528…、male → 0.2052…」
- embark_town(出港地):「Cherbourg→0.607…、Queenstown→0.285…、Southampton→0.362…」
ただし、この方法では目的変数の値が説明変数に含まれている(=リークしている)ので、見かけ上の予測精度が高くなってしまうことに注意が必要です。リークの影響を最小限にするように工夫する必要があり、実際には上記のような単純な平均値ではなく様々なテクニックを駆使した方法が用いられることになります
One-Hot Encoding
ここまで説明してきた方法はいずれもカテゴリ変数のカテゴリーを何らかの数値に置き換える方法でした。単純に0, 1, 2, … という数値に置き換えるのがLabel Encodingで、何らかの方法で重みづけを行うのがCount EncodingやTarget Encodingです。しかし、限られた情報からデータの前処理の段階で正しい重みづけを行うことは難しく、またTarget Encodingではリークの問題もあります。そこでそのような問題を解決する方法として、カテゴリ変数をそれぞれのカテゴリごとに変数(ダミー変数)に分割する方法をOne-Hot Encodingと言います。
今回の例ではembark_townのカテゴリは「Cherbourg / Queenstown / Southampton」なので、その3つのカテゴリを変数として、Yes(=1)かNo(=0)かで元のembark_townの要素を表します。
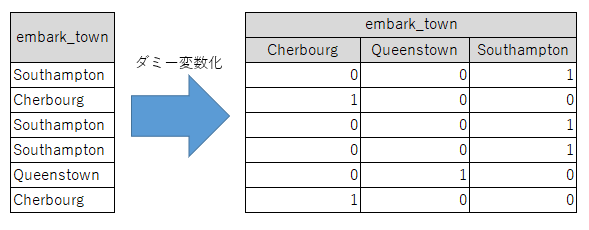
この方法ではそれぞれのカテゴリの重みづけをモデルの最適化の際に行うことができるので、今までの問題をすべて解決することができます。ただし、大量のカテゴリが含まれているカテゴリ変数の場合は、ダミー変数の数が膨大になってしまうのでこの方法を用いるのは難しい場合もあります。
なお、上記の例でいえば、embark_townが「Cherbourgか否か」とQueestownか否か」が分かれば「Southamptonか否か」は自動的に定まります。そのような場合にすべての変数をモデルに組み込んでしまうと多重共線性の問題が発生してしまうので、ダミー変数のうち1つをモデルから外すことがよく行われます。
Pythonでは、pandasのget_dummies関数を用いれば簡単にOne-Hot Encodingを行うことができます。その際にdrop_first引数をTrueに設定することで1つのダミー変数を自動で削除することができるので、多重共線性の問題を回避できます。
import pandas as pd
titanic_data = pd.get_dummies(titanic_data, drop_first=True)
print(titanic_data)
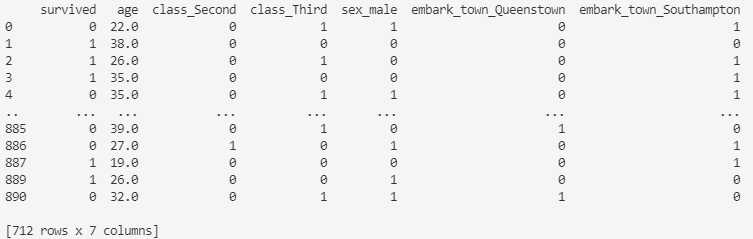
上記の例ではすべてのカテゴリ変数をダミー変数化しましたが、get_dummies関数のcolumns引数に列ラベルを指定することでそのカテゴリ変数のみをダミー変数にすることもできます。
import pandas as pd
titanic_data = pd.get_dummies(titanic_data, columns=['embark_town'], drop_first=True)
print(titanic_data)
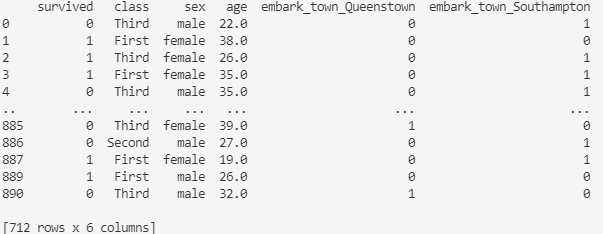
columns引数にembark_townのみを渡すことで、sexはそのままでembark_townのみをダミー変数化しました。
なお、PythonでOne-Hot Encodingを行う方法はscikit-learnやcategory_encodersなどのライブラリでも実装されています。ここに示したget_dummies関数を用いる方法ではデータセットに含まれているデータ次第で列ラベルが変化してしまうので、訓練データの「行 x 列」の形状がデータ次第で変化してしまうというデメリットがあります。データ形状を一定にする必要がある場合はscikit-learnのOneHotEncoderやcategory_encodersのOneHotEncoderを使用してください。



コメント