NumPyではndarrayの独自形式(バイナリ形式)として.npyと.npzが用意されています。1つのndarrayだけを保存する場合は.npyで、複数のndarrayをまとめて保存する場合や、圧縮して保存する場合は.npzを用います。ここではその違いと使い方について説明していきます。
開発環境
- numpy 1.19.2
- Python 3.7.9

ndarrayのバイナリ形式
ndarrayの保存形式は独自のバイナリ形式かcsvなどのテキスト形式かを選ぶことができます。テキスト形式で保存すればメモ帳やExcelなどの外部のアプリケーションで開くこともできるので他のプログラムとの連携に便利ですが、一部の情報が失われてしまう可能性があります。それに対してバイナリ形式であれば、ndarrayのすべての情報をそのまま保存することができますが、NumPy以外のライブラリでは扱うことが難しいという特徴があります。
またバイナリ形式は.npyと.npzの2種類があり、次のような使い分けがなされています。
- .npy 形式:1つのndarrayを1つのファイルとして保存する場合に用いるファイル形式
- .npz 形式:複数のndarrayを1つのファイルとして保存する場合に用いるファイル形式
また、サイズの大きいndarrayを圧縮して保存することも可能であり、その場合も.npz形式となります。
1つのndarrayを1つのファイルに保存する場合(.npy形式)
ndarrayの保存
1つのndarrayを1つのファイルとして保存する場合はsave関数を用います。第1引数にファイル名を指定し、第2引数に保存したいndarrayを指定しましょう。
import numpy as np
arr = np.array([[1,2,3],[4,5,6],[7,8,9]])
np.save('array_save.npy', arr)
これでarray.npyという名前でndarrayが保存できました。なお、ファイル名の指定は相対パスでも絶対パスでも構いません。
.npyファイルの読み込み
続いて先ほど保存した.npyファイルを読み込んでみましょう。.npyファイルを読み込むときはload関数を用いて、引数にファイル名を指定します。
import numpy as np
arr = np.load('array_save.npy')
print(arr)
[[ 1 2 3] [ 4 5 6] [ 7 8 9]]
複数のndarrayを1つのファイルに保存する場合(.npz形式)
ndarrayの保存
savez関数を使えば複数のndarrayを1つにまとめることが可能になります。第1引数にファイル名(.npz)を、第2引数以降に保存したいndarrayをカンマ区切りで順番に指定しましょう。第2引数は可変長引数(*args)なので、保存したいndarrayの数だけカンマ区切りで指定することができます。なお、ndarrayが1つの時のファイル形式は.npyでしたが、ndarrayが複数の時のファイル形式は.npzになります。
import numpy as np
arr1 = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr2 = np.array([[9,8,7],[6,5,4],[3,2,1]])
np.savez('array_save.npz', arr1, arr2)
上記のようにするとデフォルトでは引数に指定した順番で「arr_0」「arr_1」 「arr_2」という名前がついていき、.npzファイルからndarrayを呼び出すときに必要になります。この名前は次にようにキーワード引数として指定することで、保存時に指定することも可能です。
import numpy as np
arr1 = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr2 = np.array([[9,8,7],[6,5,4],[3,2,1]])
np.savez('array_save.npz', A=arr1, B=arr2)
.npzファイルの読み込み
.npz形式のファイルの読み込みもload関数ですが、load関数で.npz形式ファイルを読み込むと複数のndarrayをまとめたNpzFileオブジェクトとして取得されます。これに保存時に指定したndarrayの名前をキーとして指定することでそのndarrayを取得することができます。
先ほどのように2つのndarrayをまとめて、共にデフォルト名で保存した場合は、次のように読み込めます。
import numpy as np
arrs = np.load('array_save.npz')
print(arrs['arr_0'])
print()
print(arrs['arr_1'])
[[1 2 3] [4 5 6] [7 8 9]] [[9 8 7] [6 5 4] [3 2 1]]
なお、ndarrayの名前のリストはfiles属性で取得可能です。forループでもndarrayの名前を順番に取得することができるので、以下のようにしても同様の結果を得ることが可能です。
import numpy as np
arrs = np.load('array_save.npz')
print('ndarray名:' + str(arrs.files))
for arr_name in arrs:
print(arrs[arr_name])
print()
ndarray名:['arr_0', 'arr_1'] [[1 2 3] [4 5 6] [7 8 9]] [[9 8 7] [6 5 4] [3 2 1]]
サイズの大きいndarrayを圧縮して保存する場合(.npz形式)
巨大なndarrayはsavez_compressed関数を用いて圧縮して保存可能です。この場合はndarrayが1つの場合も複数の場合も同様で.npz形式になります。ndarrayの保存方法と.npzファイルの読み込み方法は、savez関数の場合と全く同じです。
それでは圧縮の有無でファイルサイズを比較してみましょう。
import numpy as np
arr = np.ones((1000, 1000, 1000))
np.savez_compressed('arr_compressed.npz', arr)
np.save('arr.npy', arr)
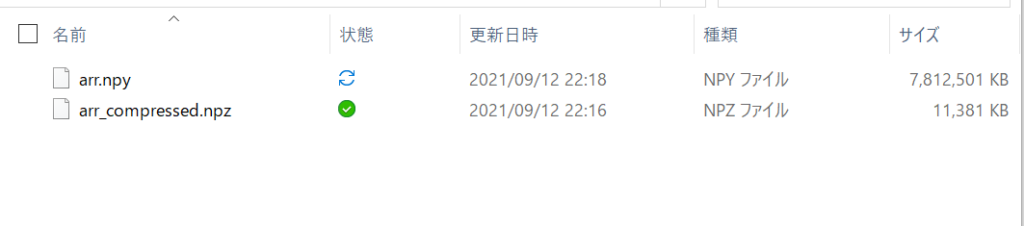
圧縮なしの場合は7.8GBのサイズだったのが、圧縮することで11MBまで削減できていることが分かります。ただし、この例ではすべて同じ値のndarrayだったので圧縮により顕著な差が出ていますが、実際の例ではここまで大きな差は出ないと思われます。また、ファイルの保存・読み込みは圧縮・解凍の時間が必要なので遅くなりますので、注意が必要です。



コメント